

Benchmarking ScaleDown’s Extraction SLM on CUAD
Higher accuracy at 60% lower cost on legal contract extraction

Contract review is one of the most tedious, expensive, and error-prone tasks in legal work. A single M&A transaction can involve hundreds of contracts, each requiring a lawyer to locate and extract specific clauses, such as governing law, expiration dates, renewal terms, and party names. It’s a needle-in-a-haystack problem repeated thousands of times.
We benchmarked ScaleDown’s extraction endpoint against GPT-5.4 Mini on CUAD (Contract Understanding Atticus Dataset): 510 real commercial contracts, expert-annotated by lawyers from The Atticus Project to measure how a purpose-built extraction model compares to a general-purpose LLM on this task.

The Dataset
CUAD (Hendrycks et al., 2021) is a legal AI benchmark consisting of 510 commercial contracts sourced from SEC EDGAR filings. The full dataset has 41 clause categories annotated by law students under the supervision of experienced lawyers. Most of those 41 categories are binary (does this clause exist?), but a subset requires actual extraction: the model must find and return a verbatim text span from the contract.
We focused on the 8 extraction-type fields
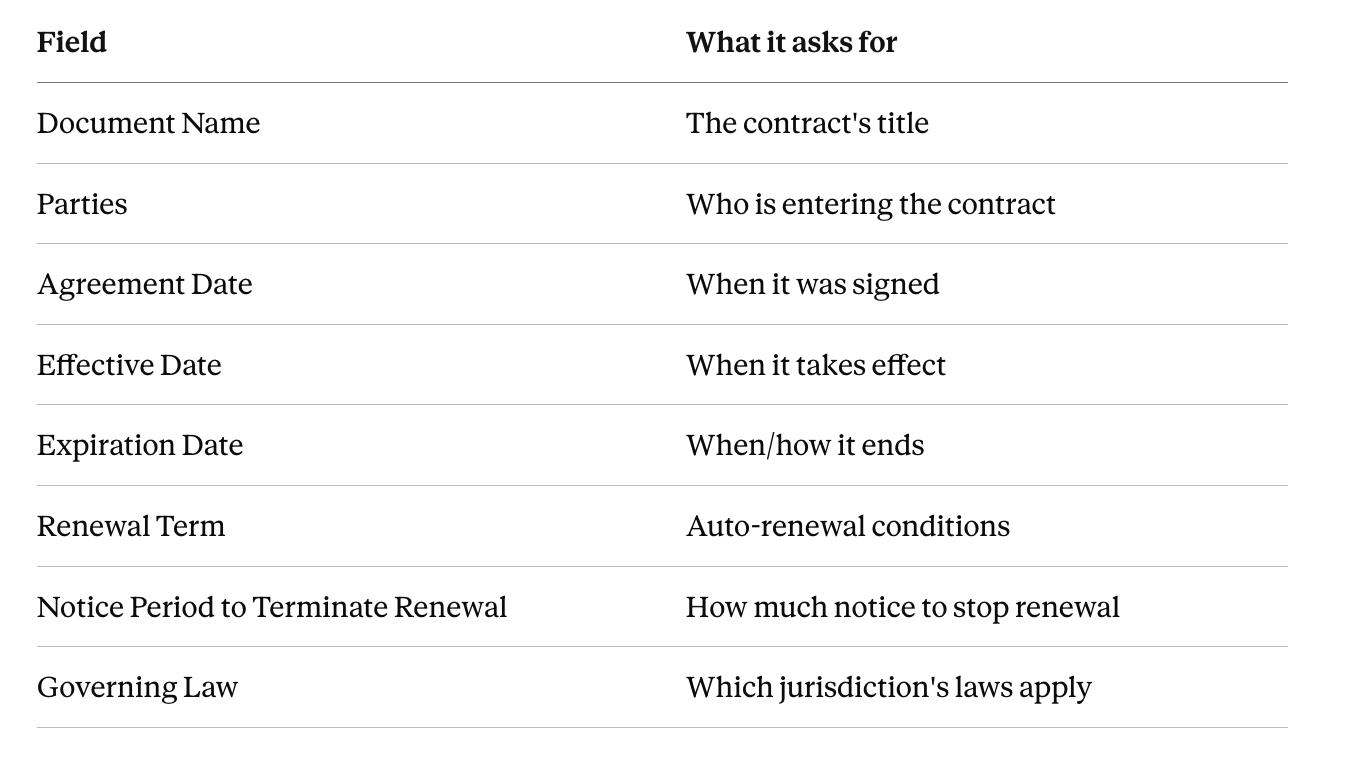
What We Compared
ScaleDown /extract/ endpoint
A purpose-built entity extraction API. You send it a contract text and a dict of {entity_type: description}, and it returns extracted spans with confidence scores. One API call per (contract, field) pair.
Pricing: $0.05/1M tokens in, $0 for tokens out.
GPT-5.4 Mini (baseline)
Standard LLM prompted with a natural-language extraction instruction. The system prompt instructs the model to extract the exact text span from the contract. The full contract goes into the user message along with the field name and description.
Pricing: $0.15/1M input, $0.60/1M output.
The Benchmarking Process
Dataset loading. We pulled CUAD_v1.json from HuggingFace (theatticusproject/cuad). It’s in SQuAD format, nested as data → paragraphs → qas. We flattened each (contract, field) pair into individual examples.
Prompt construction. For ScaleDown, the entity type and a natural-language description of what to extract are sent as the API payload. For GPT-5.4 Mini, the full contract text goes into the user message with an instruction to extract verbatim text.
Metrics. We use two standard metrics from the extractive QA literature:
Exact Match (EM): 1.0 if the normalized prediction exactly equals any of the gold reference spans, 0.0 otherwise. Normalization is lowercase plus whitespace collapsing. No punctuation stripping, since legal dates and clause punctuation matter.
F1: Token-overlap F1 between prediction and gold, taking the max across multiple gold references. Better for longer clauses where partial credit is meaningful if the model extracts 90% of a governing law clause correctly, F1 captures that while EM counts it as a miss.
Results
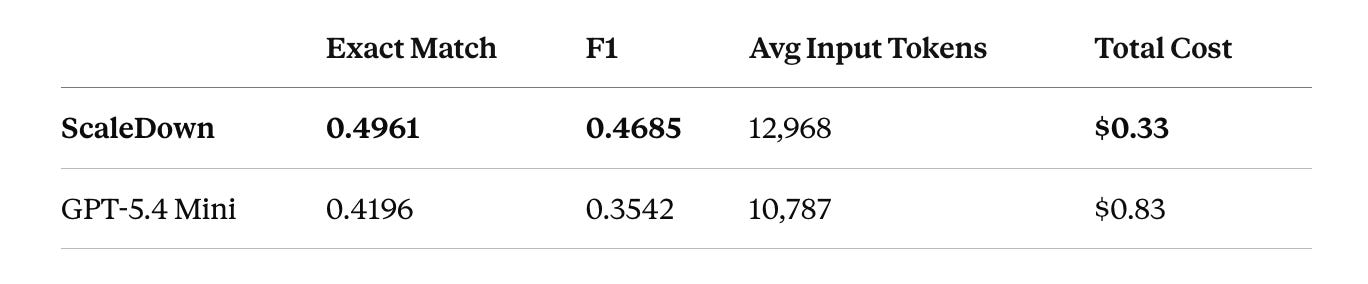
ScaleDown is more accurate on both metrics. Exact match is 0.4961 vs. 0.4196, a +7.65 point improvement. F1 is 0.4685 vs. 0.3542, a +11.43 point improvement. The F1 gap being larger than the EM gap tells us that even when ScaleDown doesn’t hit an exact match, it’s extracting spans that overlap substantially with the gold answer. GPT-5.4 Mini’s misses are further from the target.
ScaleDown costs 60% less. Total cost across 510 examples: $0.33 vs. $0.83. This is driven by ScaleDown’s pricing ($0.05/1M tokens in) vs. GPT-5.4 Mini’s asymmetric pricing ($0.15/1M input, $0.60/1M output). At production volumes, for a legal tech company processing thousands of contracts per month, this delta compounds quickly.
Why a Purpose-Built Extractor Wins Here
Legal contract extraction is a pattern-matching task over long, structured documents. The model needs to locate a specific span in a specific section of a contract that might be 10,000+ tokens long. It doesn’t need to reason about the clause, paraphrase it, or generate a summary. It needs to find the right text and return it verbatim.
GPT-5.4 Mini approaches this as a generation task. It reads the contract, reasons about the question, and generates a response that (hopefully) contains the exact span. This introduces several failure modes: the model paraphrases instead of quoting, hallucinates a plausible-looking date that doesn’t appear in the contract, or returns a span that’s close but not exactly aligned with the gold annotation.
ScaleDown’s extraction model is built to locate and return spans, not generate text. The task is architecturally matched to the model’s design. This is the same pattern we see across all our benchmarks: when the task is well-defined and doesn’t require open-ended generation, a purpose-built model dominates.
Reproducing the Benchmark
Run via ScaleBench:
git clone https://github.com/scaledown-team/scalebench
cd scalebench
uv venv && source .venv/bin/activate
uv pip install -r requirements.txt
Set your API keys in .env:
OPENAI_API_KEY=your_key
SCALEDOWN_API_KEY=your_key
Run the CUAD experiments:
uv run python scripts/run_benchmarks.py --experiment-id cuad_extraction_scaledown
uv run python scripts/run_benchmarks.py --experiment-id cuad_extraction_openai_baseline
Results land in results/summaries/ with per-experiment metrics, cost, and latency breakdowns.
Key Takeaways
On 510 real commercial contracts with expert annotations, ScaleDown’s extraction model outperforms GPT-5.4 Mini on both exact match (+7.65 points) and F1 (+11.43 points), while costing 60% less. The accuracy improvement comes from architectural fit: extraction is a span-location task, not a generation task, and a model designed for span location does it better.
For legal tech teams processing contracts at scale, the extraction endpoint handles the structured fields — parties, dates, governing law, renewal terms — while freeing up the LLM budget for tasks that actually require generation: clause summarization, risk assessment, and negotiation analysis.
We offer 50M free tokens for every agent. Try it at scaledown.ai.