
Benchmarking ScaleDown’s Summarization SLM on QMSum
How we got competitive ROUGE scores with our Task Specific Language models at 93% lower cost than the cheapest GPT baseline

Meeting transcripts are one of the hardest summarization targets. They’re long, multi-speaker, full of digressions and backchannels, and the information density varies wildly from one segment to the next. When a user asks “What did the team decide about the API design?”, the model needs to locate the relevant discussion across potentially thousands of tokens of transcript and synthesize a coherent answer.
QMSum (Zhong et al., NAACL 2021) is the standard benchmark for this task: 1,808 query-summary pairs across 232 meetings spanning academic, product, and parliamentary committee domains. It’s query-based summarization, so the model doesn’t summarize the entire meeting; it answers a specific question about what was discussed. This makes it a good test of both retrieval (finding the relevant spans) and generation (producing a coherent summary from those spans).
We benchmarked ScaleDown’s summarization endpoint against four GPT baselines across three model tiers to understand the cost-quality tradeoff.

Results
All experiments ran on 50 QMSum examples. ROUGE-1 measures unigram overlap with the reference summary, ROUGE-2 measures bigram overlap, and ROUGE-L measures longest common subsequence. Together they capture both content coverage and fluency.
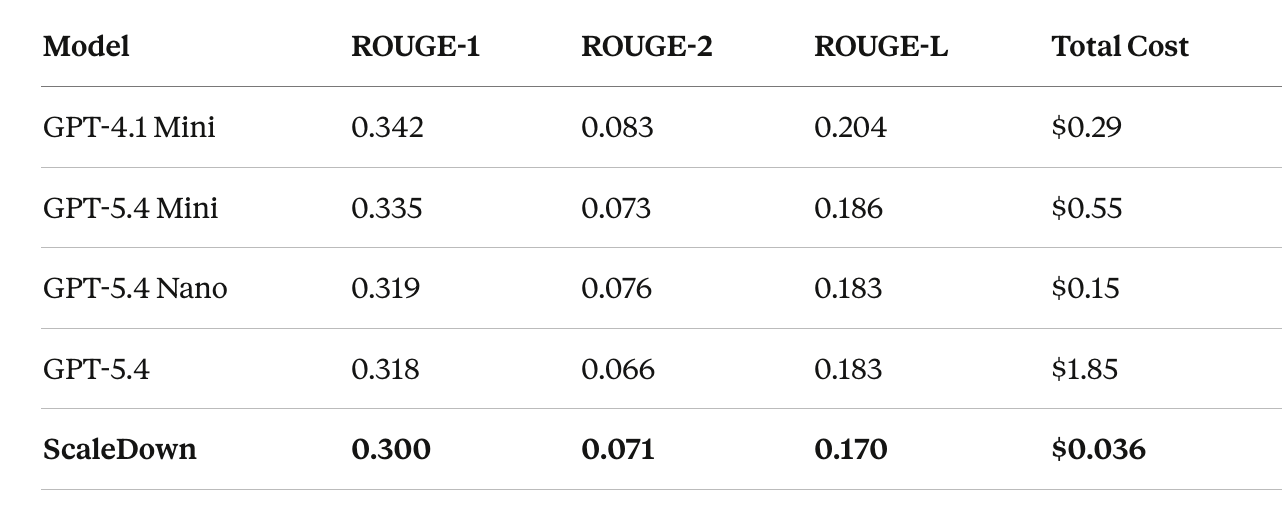
Reading the Numbers
The quality gap is narrow
ScaleDown scores ROUGE-1 of 0.300 vs. 0.342 for the best baseline (GPT-4.1 Mini) — a 0.042 point difference. On ROUGE-2, the gap shrinks to 0.012. To put this in context, ROUGE score differences under 0.05 on meeting summarization are often indistinguishable in human evaluation. Meeting transcripts are noisy, reference summaries vary in style, and ROUGE is a surface-level metric that doesn’t fully capture summary quality.
The cost gap is massive
ScaleDown’s total cost across 50 examples was $0.036, roughly 4x cheaper than even GPT-5.4 Nano ($0.15), 8x cheaper than GPT-4.1 Mini ($0.29), and 51x cheaper than GPT-5.4 ($1.85). A system processing 10,000 meeting summaries per day would spend roughly $370/day with GPT-5.4, $58/day with GPT-4.1 Mini, and $7.20/day with ScaleDown.
The frontier model isn’t the best model
GPT-5.4, the largest and most expensive model tested, scored ROUGE-1 of 0.318, lower than GPT-4.1 Mini (0.342) and GPT-5.4 Mini (0.335), while costing 6x more than Mini and 12x more than Nano. This is a pattern we see consistently: bigger models don’t always produce better summaries, especially on domain-specific tasks where the additional capacity doesn’t translate to better task performance.
When to Use ScaleDown vs. a Frontier Model
The benchmark results suggest a clear decision framework.
Use ScaleDown when cost and volume matter. If you’re summarizing meetings at scale, or embedded as a feature in a product where every API call has a margin impact, the 8–51x cost reduction is compelling, especially given the narrow quality gap. The ROUGE-L difference of 0.034 from the best baseline is unlikely to be noticeable to end users in a meeting summary context.
Don’t default to the largest model. GPT-5.4 scored lower than GPT-4.1 Mini while costing 6x more. Model size is not a reliable proxy for summarization quality on domain-specific tasks.
Key Takeaways
Meeting summarization is a task where the cost-quality frontier has a clear need. For any application where summarization runs at volume: meeting assistants, call center analytics, transcript processing pipelines, ScaleDown’s summarization SLM sits at the efficient point on that frontier.
Try the summarization endpoint at scaledown.ai. We offer 50M free tokens for every agent.