
Context Compression for Data Security and Privacy Platforms
Why extractive SLMs for pruning long contexts are a natural fit for code-to-cloud data intelligence

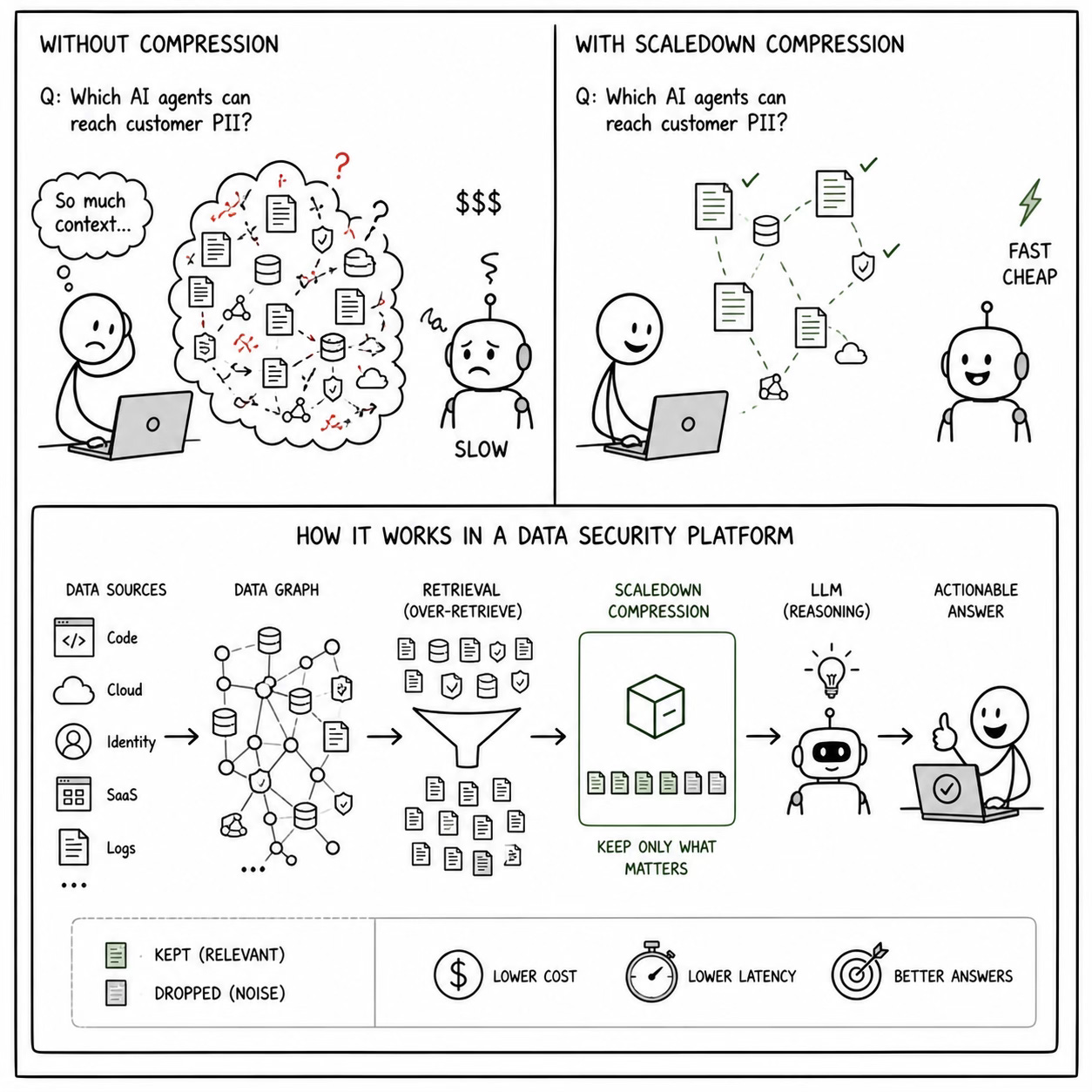
If you’re building a platform that traces how sensitive data moves through an organization, from source code to cloud infrastructure to AI models, you’re dealing with a context problem that scales faster than your LLM budget.
These platforms generate enormous volumes of contextual data: code-level data flow graphs, API call traces, identity-to-data access chains, policy obligation mappings, SaaS integration metadata, and AI agent behavior logs. When a security analyst asks “Which AI agents can reach customer PII in production?”, the system needs to reason over all of it. The typical approach is to throw it all into a frontier LLM context window and hope for the best.
That approach breaks in three predictable ways.
The Three Failure Modes
Cost scales super-linearly. A data security platform that traces data journeys across an enterprise might need to correlate information from code scanners, runtime monitors, cloud configurations, identity providers, and regulatory databases, all in a single query. A single analyst question can easily require 50k-100k tokens of context. Multiply that by the number of queries per day across a security team, and you’re looking at inference costs that make the CFO nervous.
Latency kills the experience. Security analysts don’t file tickets and wait. They’re investigating an incident, triaging an alert, or answering a compliance auditor. If your AI-powered assistant takes 15 seconds to respond because it’s processing 80k tokens of data flow context, the analyst goes back to manually querying dashboards. The whole point of the AI layer: turning natural language questions into contextual answers collapses.
Noise degrades quality. This is the one people underestimate. When you dump an entire data lineage graph into a context window, the model has to figure out what’s relevant on its own. It often can’t. It hallucinates connections between unrelated data flows, confuses identity chains, or misattributes policy violations. More context doesn’t mean better answers, it often means worse ones.
Where Context Compression Fits
This is the problem that ScaleDown’s compression model was designed to solve, and data security platforms are one of the clearest production use cases we’ve seen.
Our compression endpoint sits between the data retrieval layer and the LLM. It takes the full context: all the data flow traces, policy mappings, identity chains, whatever the retrieval system pulls and extracts only the sentences that are relevant to the specific query. The LLM never sees the noise.
Here’s what matters about our approach for this use case:
It’s extractive, not abstractive. The model doesn’t rewrite or summarize the context. It selects which sentences to keep and which to drop. In a security and compliance setting, this is critical. You cannot have a compression layer that paraphrases a GDPR obligation or rewrites the access path between an AI agent and a data store. The original language has to be preserved exactly. Our model gives you that guarantee by design. It never generates text, so it can never hallucinate.
It’s query-aware. The compression isn’t generic. When a privacy analyst asks “Are we GDPR Article 30 compliant right now?”, the model selects different sentences from the same context than when a security analyst asks “What changed in our data flows since Tuesday?” The same underlying data gets compressed differently depending on what the user actually needs to know. This is a fundamental property of our SLM: it scores relevance at the token level, conditioned on the query.
It’s fast. The compression model is a small language model, small enough to run inference on long contexts at low latency. For a data security platform handling analyst queries in real time, this means the compression step doesn’t meaningfully add to the response time. You can compress 100k tokens of context in a fraction of the time it would take a frontier model to read that same context.
Architecture: Where It Actually Goes
Let me get concrete about where this fits in the stack of a data security platform.
A typical architecture for this kind of platform looks something like:
Data collection layer: Code scanners, runtime monitors, API integrations with cloud providers, SaaS connectors, identity providers.
Data graph: A continuously updated graph of how data flows from code to cloud to AI. Think of it as a living map of data movement.
Query interface: An AI assistant that lets analysts ask questions in natural language and get contextual answers.
Policy engine: Maps data flows to legal, contractual, and regulatory obligations.
The compression endpoint slots in at step 3, between the retrieval system and the LLM:
Analyst Query
↓
Retrieval System (pulls relevant subgraphs, policies, identity chains)
↓
ScaleDown Compression (extracts query-relevant sentences)
↓
Frontier LLM (reasons over compressed context)
↓
Contextual Answer
The retrieval system does the broad strokes: it knows which data flows, policies, and identities are potentially relevant. But it over-retrieves by design, because missing a relevant data flow is worse than including an irrelevant one. The compression model handles the precision: it takes the over-retrieved context and prunes it down to exactly what the LLM needs.
Concrete Scenarios
Breach blast radius analysis. An analyst gets an alert that a third-party vendor’s API has been compromised. They ask: “What sensitive data could have been exposed through the Vendor X integration?” The retrieval system pulls every data flow touching that vendor — possibly spanning dozens of services, data stores, and processing pipelines. Most of it is irrelevant to the specific breach vector. The compression model extracts the sentences describing the data categories flowing through the compromised endpoint, the identity chains that could have been exploited, and the downstream systems that received data from that vendor. The LLM gets a clean, focused context and produces an accurate blast radius assessment.
Shadow AI detection triage. A security team discovers an unapproved AI service being used by an engineering team. The query: “What data is flowing to this service and does it violate any policies?” The retrieval system surfaces the full data lineage for the relevant engineering team’s infrastructure, plus the complete policy database. That’s a lot of context. Compression strips it down to the specific data flows touching the unauthorized service, the sensitivity classification of the data involved, and the specific policy clauses that apply.
The Economics
Here’s a back-of-the-envelope calculation that matters for anyone building or buying this kind of platform.
Assume an analyst query requires 80k tokens of context to answer comprehensively. At GPT-5.5 pricing, that’s roughly $0.40 per query in input tokens alone. A security team running 500 queries per day is spending $200/day, or $6,000/month, just on input tokens for the analyst interface.
ScaleDown’s compression endpoint sits between the data retrieval layer and the LLM. It takes the full context and extracts only the sentences that are relevant to the specific query. The LLM never sees the noise. And you never pay for it.
With ScaleDown compression achieving 40-60% token reduction while preserving answer quality, the same workload drops to $2,400-$3,600/month. The compression inference itself costs a fraction of that. Multiply by multiple teams (security, privacy, engineering) and the savings compound.
For enterprise deployments running $15,000-$25,000/month in uncompressed token costs, the annual savings range from $90,000 to $150,000.
But the cost argument is the least interesting one. The quality argument is stronger: compressed contexts produce more focused answers with fewer hallucinations. And the latency argument is strongest of all: faster responses mean analysts actually use the tool instead of reverting to manual workflows.
Why Extractive Matters for Compliance
I want to hammer this point because it’s specific to the security and compliance domain. If you’re building a consumer chatbot or a content generation tool, abstractive compression (summarization) might be fine. You lose some nuance, but the use case is forgiving.
In data security and privacy, the use case is not forgiving. When an analyst asks about GDPR compliance, the system’s answer needs to be traceable to specific policy language, specific data flow observations, and specific regulatory clauses. If the compression layer rewrites any of these the answer loses its evidentiary value.
Extractive compression preserves the original text. Every sentence in the compressed output is a verbatim sentence from the source context. The compression model decides which sentences to keep, but it doesn’t change them. This means the LLM’s reasoning chain is fully traceable: you can show exactly which source sentences informed the answer.
Getting Started
If you’re building a data security, privacy, or AI governance platform and you’re hitting context window, cost, or quality limits on your AI features, this is worth testing. The ScaleDown API is straightforward: you send the context and the query, and you get back the compressed context. No model training, no infrastructure changes.
We offer 50M free tokens for every agent. Try it at scaledown.ai and let us know what you’re building. We’re particularly interested in hearing from teams working on data security and AI governance, this is a domain where the compression quality really shows.