
Extraction SLMs for E-Commerce Chatbots and Voice Agents: Stop Paying Frontier Prices for Structured Data
How task-specific extraction models cut 80%+ off the most expensive call in your customer service AI pipeline

If you’re running an AI-powered customer service chatbot or voice agent for an e-commerce retailer, you’re probably paying frontier LLM prices for a task that doesn’t need a frontier LLM.
That task is entity extraction: pulling structured data out of messy customer messages. It’s the first step in nearly every customer interaction, and it happens on every single query.
When the customer says something, the system needs to figure out what product they’re talking about, what they want to do with it, what their order number is, and what constraints apply. It uses this information to route the conversation, query a backend system, or generate a response.
Most teams solve this with the best GPT or Claude model. It works, but the cost becomes unsustainable at scale, and it gets worse as you add more channels and products.
The Cost Problem Is Worse Than You Think
An omnichannel retailer with TV shopping, a website, a mobile app, and 24/7 phone and chat support might handle 50,000-100,000 customer service interactions per month. Each interaction involves multiple turns, and each turn requires extraction.
A typical customer service exchange looks like this:
Customer: “Hi, I bought a tanzanite ring on the show last Thursday using BudgetPay and the stone looks different from what was on TV. I want to exchange it but I already threw away the jewelry box.”
From this single message, the system needs to extract:
Product type: tanzanite ring
Purchase channel: TV show
Purchase timing: last Thursday
Payment method: BudgetPay (installment plan)
Issue type: product doesn’t match description
Desired action: exchange
Exception condition: original packaging missing
That’s seven structured fields from one conversational sentence. And this is a simple case. Jewelry and gemstone retail adds layers of complexity: customers reference carat weights, metal types (sterling silver vs. 18K gold vermeil), certifications, brand names, auction lot numbers, and show times. They mix product attributes with emotional language: “the beautiful blue one with the little diamonds around it that Lisa showed around 8pm.”
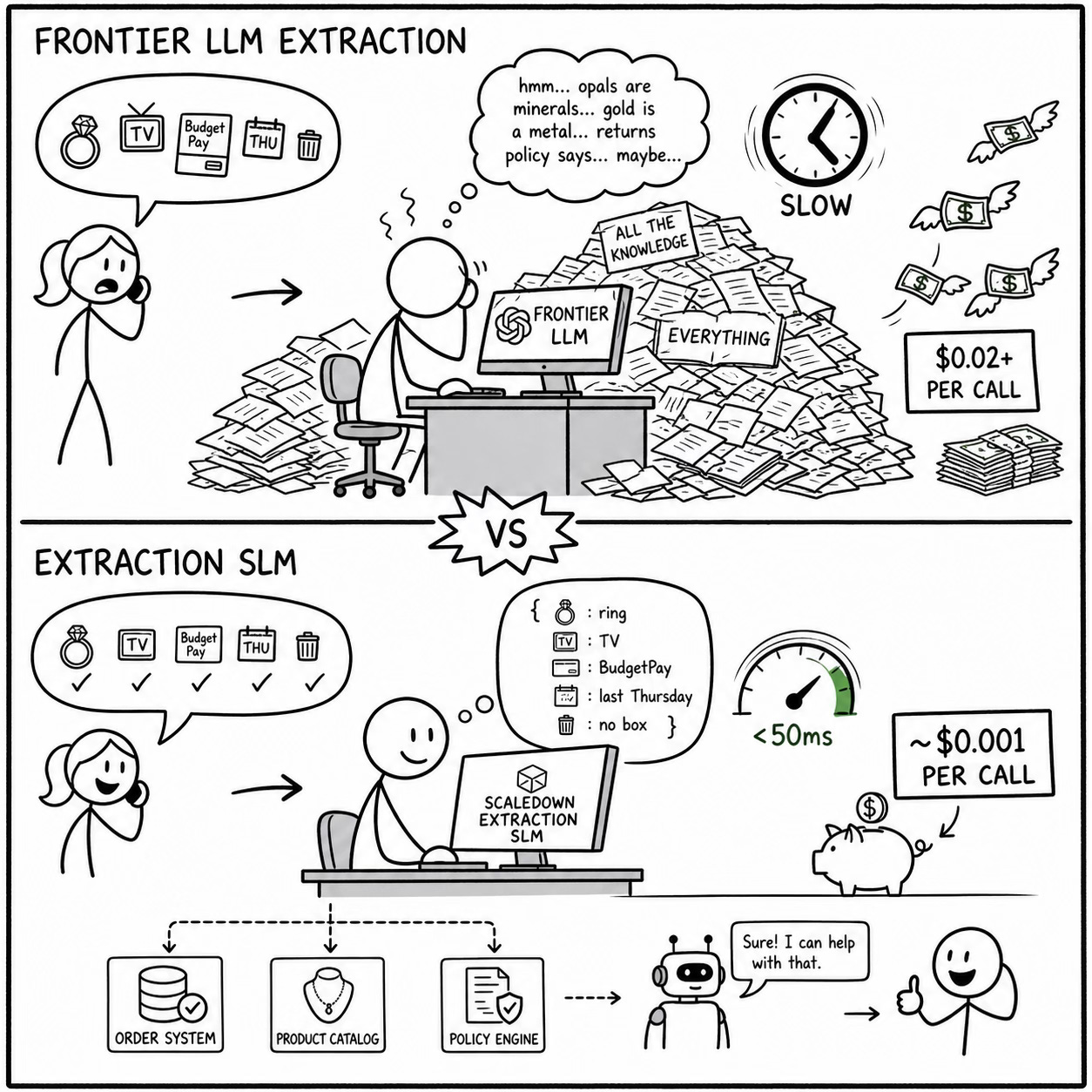
Using a frontier LLM for this extraction, you’re spending roughly $0.01-$0.03 per extraction call, depending on prompt length and model. At 50,000 interactions per month with an average of 3 extraction calls per interaction (initial message, follow-up clarification, resolution confirmation), that’s 150,000 extraction calls, resulting in $1,500-$4,500/month just on extraction.
And extraction is only one step. You still need the LLM for response generation, product recommendation, policy lookup reasoning, and escalation decisions. Extraction is consuming a large chunk of your AI budget for what is fundamentally a structured data task, not a reasoning task.
Why Extraction Is Not a Reasoning Task
This distinction matters because it’s where the cost savings live.
When a customer says “I want to return the opal earrings,” the system doesn’t need to reason about opals. It doesn’t need world knowledge about opal hardness, origin, or market value. It needs to identify that “opal” is a gemstone type, “earrings” is a product category, and “return” is an intent. This is pattern matching over a known schema, not open-ended reasoning.
A frontier LLM brings its entire parameter space to this task: its knowledge of opals, earrings, customer service best practices, the English language, and everything else it learned during training. You’re paying for all of that knowledge when you only need a tiny fraction of it.
A task-specific extraction SLM (Small Language Model) is trained to do one thing: map unstructured text to a defined output schema. It learns the retailer’s product taxonomy (gemstone types, metal types, brand names, product categories), the common customer intents (return, exchange, track order, BudgetPay inquiry, auction question), and the entity types that matter (order ID, show date/time, product attributes, payment method, exception conditions).
At ScaleDown, our extraction models handle this at a fraction of the cost of a frontier model call. For the same 150,000 extraction calls per month, you would spend about $0.001 per API call, resulting in a monthly bill of $30.
Latency: The Voice Agent Constraint
Cost is the primary argument, but latency is what makes extraction SLMs mandatory for voice agents rather than merely preferable.
A voice agent has a hard latency budget. When a customer finishes speaking, the system needs to extract entities, query backends, and generate a response before the silence becomes awkward. The entire pipeline: speech-to-text, extraction, backend query, response generation, text-to-speech, has maybe 1.5-2 seconds to complete.
A frontier LLM extraction call can take 300ms depending on prompt complexity and API load. That’s consuming a significant portion of the total latency budget in a single step. If the extraction call takes 1 second on a bad day, the customer hears dead air while the system catches up.
Our extraction SLM returns results in under 50ms. That frees up 250ms of latency budget for the steps that actually need it: the backend query and the response generation.
Accuracy: Domain-Specific Extraction Beats General-Purpose
Here’s the counterintuitive argument: a smaller, task-specific model is often more accurate than a frontier model for e-commerce entity extraction, because it doesn’t get confused by irrelevant knowledge.
Consider this customer message: “I got the Luxoro 14K gold ring with the AAA Ethiopian opal, the one from the Tuesday 9pm auction, and the clasp on the ring box is broken.”
A frontier model knows a lot about opals, gold purity, and Ethiopian gemstone mining. This knowledge can actually interfere with extraction. The model might classify “Ethiopian” as a geographic entity rather than a gemstone origin qualifier. It might interpret “AAA” as a rating agency rather than a gemstone quality grade. It might get confused about whether “Luxoro” is a brand name or a product description.
A task-specific model trained on the retailer’s product taxonomy knows that “Luxoro” is a brand, “AAA” is a gemstone grade in this context, “Ethiopian” modifies the opal origin, “14K gold” is a metal type, and “Tuesday 9pm” is a show time. It extracts all seven entities cleanly because its entire training is focused on this domain.
This accuracy advantage compounds over time. Every misextracted entity means a wrong backend query, which means a wrong response, which means a frustrated customer who has to repeat themselves. At scale, even a 2-3% improvement in extraction accuracy translates to thousands of fewer escalations per month — which is its own cost savings.
Architecture: Where Extraction Fits in the Stack
Here’s the concrete architecture for an e-commerce customer service AI that uses extraction SLMs:
Customer Message (chat, voice transcript, email, DM)
↓
ScaleDown Extraction SLM (<50ms, ~$0.001)
→ Structured entities: {product, intent, order_id, attributes, constraints}
↓
Backend Query (order system, product catalog, policy engine)
→ Order status, product details, applicable policies
↓
Context Assembly (extracted entities + backend results + conversation history)
↓
Frontier LLM (generates conversational response)
↓
Customer Response
The extraction SLM handles the first step: the high-volume, latency-sensitive structured-data task. The frontier LLM handles the last step, the one that actually requires generative capabilities. Everything in between is deterministic backend logic.
This separation means you can optimize each component independently. Swap extraction models without touching response generation. Scale extraction separately from generation. Monitor extraction accuracy independently from response quality. The frontier model only gets involved when its capabilities are actually needed: generating a natural, empathetic, brand-appropriate response.
Getting Started
If you’re running customer service AI for a retail operation, especially one with a large product catalog and multiple support channels, extraction is almost certainly your highest-volume LLM call. It’s also the one most likely to be overpaying for.
The question to ask: does pulling structured entities from customer messages require the reasoning capabilities of a frontier model? For the vast majority of e-commerce extraction tasks, the answer is no. You need fast, accurate pattern matching over a known schema. That’s what task-specific SLMs are built for.
We offer 50M free tokens for every agent. Try it at scaledown.ai. If you’re in retail, especially jewelry, fashion, or any domain with complex product attributes, we’d love to hear about your extraction schema.