
Intent Classification for AI Financial Planners
You Don’t Need a Frontier Model to Route a Query. Task-specific classification SLMs solves this bottleneck in financial planning AI.

There’s a class of AI product that’s becoming common in fintech: conversational planning assistants that sit on top of deterministic financial engines. The user asks a question in plain language, “Can I retire at 62?” or “Should I do a Roth conversion this year?”, and the system figures out what scenario to run, executes it through a financial modeling engine, and then uses an LLM to explain the results.
It’s a smart architecture. The engine handles the math, the LLM handles the explanation. No hallucinated numbers.
But there’s a step before any of that happens that most teams are solving with a frontier LLM, and it’s a mistake. That step is intent classification: figuring out what the user is actually asking, so the system knows which scenario to run.
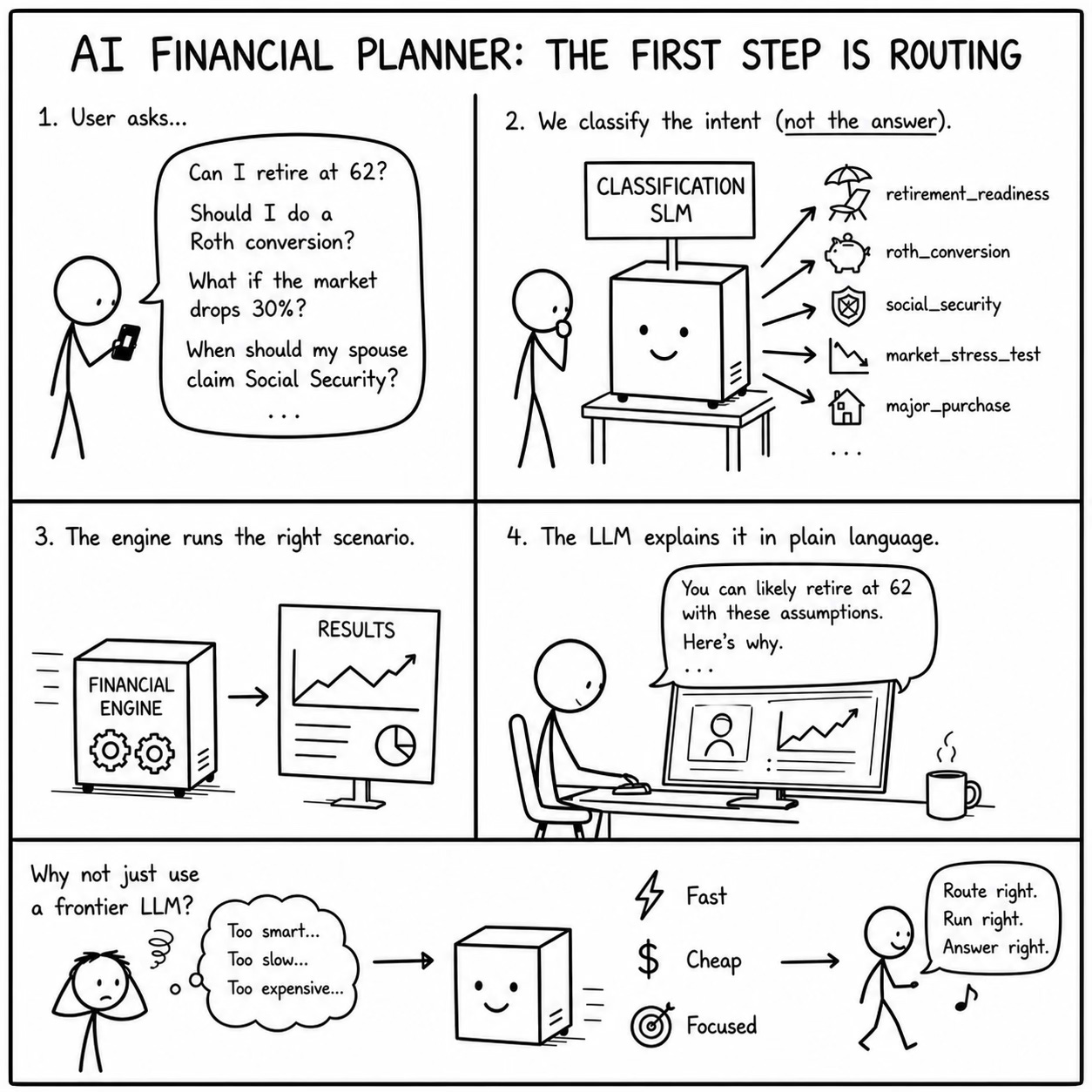
The Classification Problem
When a user types “What happens if the market drops 30% next year?”, the system needs to classify this as a market stress test scenario before it can do anything useful. When they type “When should my spouse start collecting Social Security?”, that’s a Social Security claiming strategy query. “Am I saving enough?” is a retirement readiness assessment. “How much can I convert this year without bumping into the next bracket?” is a Roth conversion optimization question.
These questions require different computational paths through the financial engine. A Roth conversion query needs the engine to run a matrix of conversion amounts across projected tax brackets. A market stress test needs a Monte Carlo simulation with a specified drawdown. A Social Security query needs to calculate benefits at every possible claiming age for both spouses under different longevity assumptions.
Most teams today solve this with a frontier LLM. The user’s query goes into GPT or Claude, along with a system prompt that describes the available scenario types, and the model classifies the intent. This works. But it has three problems that get worse at scale.
Problem 1: Cost at Volume
Classification is the most frequent LLM call in this architecture. Every single user query needs to be classified. If the system handles follow-up questions, many of those follow-ups need reclassification too, because the user might shift from asking about retirement timing to asking about tax impact within the same session.
On average, a classification call might cost $0.01 in frontier model tokens (a conservative estimate for a prompt that includes the full taxonomy of scenario types). For 200k API calls a day, that’s $2,000 in classification costs alone.
Problem 2: Latency Stacks
The classification call is upstream of everything else. The system can’t start running the financial engine until it knows which scenario type to execute. It can’t start assembling context for the explanation LLM until the engine finishes. Every millisecond of latency in the classification step delays the entire pipeline.
A frontier LLM classification call typically takes 500ms-2s, depending on prompt complexity and load. For a conversational financial planner where users expect near-instant responses, this is a meaningful chunk of the total response time, and it’s being spent on what is fundamentally a simple routing task.
Problem 3: Overqualified and Under-Specialized
Here’s the counterintuitive thing. Frontier LLMs are actually worse at intent classification for financial planning queries than a properly trained small model, because they know too much.
When a user asks “Should I take money out of my IRA?”, a frontier model’s world knowledge about IRAs: penalties, RMDs, Roth vs. Traditional, hardship withdrawals, 72(t) distributions can cause it to over-interpret the query. It might classify this as a withdrawal optimization query when the user was actually asking a simple retirement income question. The frontier model’s broad knowledge becomes noise that interferes with the narrow classification task.
A task-specific classification model trained on financial planning query patterns learns the mapping between query language and scenario types without the baggage of encyclopedic financial knowledge. It learns that “take money out” in this product context means “retirement income modeling,” not “early withdrawal penalty calculation.” It learns the product’s taxonomy, not the world’s taxonomy.
Where ScaleDown’s Classification Model Fits
This is exactly the kind of task we build models for at ScaleDown. Our classification SLMs are purpose-built for high-volume, latency-sensitive classification where a frontier model is overkill.
For a financial planning AI assistant, the classification model handles the first step in the pipeline:
User Query ("Can I afford to buy a lake house next year?")
↓
ScaleDown Classification SLM
→ Intent: major_purchase_scenario
→ Sub-intent: real_estate_acquisition
→ Required engine params: purchase_price, timing, financing
↓
Parameter Extraction (what price? what timing?)
↓
Financial Planning Engine (runs the scenario)
↓
LLM Explanation (interprets results in plain language)
↓
Personalized Answer
The classification model handles the routing decision. It doesn’t need to understand IRAs or Monte Carlo simulations or FICO scores. It needs to map natural language queries to a fixed set of scenario types and it needs to do it in single-digit milliseconds at pennies per thousand queries.
Getting Started
If you’re building a financial planning assistant or any conversational AI where query routing is the first step in a multi-stage pipeline, classification SLMs are worth evaluating.
The core question is: does your classification task justify the latency and cost of a frontier model? If you’re routing to a fixed taxonomy of 15-50 intent categories, the answer is almost certainly no. A task-specific model will be faster, cheaper, and often more accurate on the narrow task.
We offer 50M free tokens for every agent. Try it at scaledown.ai. If you’re working on financial planning AI specifically, we’d love to hear about your intent taxonomy. It’s one of the more interesting classification problems we’ve seen, and the domain-specific edge cases are where these models really earn their keep.