

Introduction to Large Language Models (LLMs): An Informative and Approachable Guide
A Closer Look at LLMs: Understanding the Key Concepts and Terminologies

Hello everyone,
I've realized that some of our past newsletters have been pretty technical, and while that's great for those well-versed in LLMs, it could be a bit daunting for beginners. So, I've decided to take a different approach and simplify things. Today, we're embarking on a fascinating adventure - a beginner-friendly, storylike journey through the evolution of Large Language Models (LLMs) like ChatGPT. By the end, you'll not only be equipped with basic knowledge but also have a fun guide for our future newsletters.
In this edition, our objectives are:
Understand the evolution of Large Language Models (LLMs), like ChatGPT
Comprehend key terminologies used in relation to LLMs
Understand the key differences in how LLMs approach a problem and how we do it
Section 1: The Era Before Transformers (Before 2017)
Before the advent of Transformer models in 2017, there were two key models for handling sequence data: Recurrent Neural Networks (RNNs) and Convolutional Neural Networks (CNNs). Both of these models served their purpose but had their limitations.
RNNs, as the name suggests, process data in a recurring sequence. This was useful for tasks that required an understanding of context over time, such as translating a sentence. However, RNNs struggled to maintain context over long sequences, leading to the "vanishing gradient problem," a well-documented challenge in the field of deep learning. RNNs and the Vanishing Gradient Problem
 - The Vanishing Gradient Problem - Blogs - SuperDataScience | Machine Learning | AI | Data Science Career | Analytics | Success")
On the other hand, CNNs, traditionally used for image processing, were also adopted for handling sequential data. The ability of CNNs to process input data in parallel made them faster and more scalable than RNNs. However, they were less adept than RNNs at capturing temporal dependencies, meaning they struggled with sequence data where the order was important. CNNs and Temporal Dependencies
Section 2: Tokenization
Both RNNs and CNNs required significant data preprocessing. Enter tokenization, a crucial step in the process. Tokenization is the act of splitting a sentence into individual words or characters, referred to as tokens. Essentially, it's like chopping a sentence into bite-sized pieces so that the model can analyze each piece one at a time. Understanding tokenization is fundamental to appreciating how LLMs process and understand language. The Importance of Tokenization

Section 3: Enter the Transformers (2017)
The Transformer model, introduced in 2017 by Vaswani et al. at Google Brain, was a groundbreaking innovation in the field of NLP. This model was revolutionary in its ability to process all tokens in the input data in parallel (like CNNs) while also maintaining a sense of order or sequence (like RNNs). This new approach was encapsulated in their seminal paper, "Attention is All You Need".
One of the defining features of the Transformer model is its use of the "attention mechanism." This mechanism allows the model to weigh the relevance of each token in context, giving more "attention" to tokens that are likely to influence the meaning of the next token. For instance, in the sentence "I took my dog for ___", a transformer model would pay more attention to "dog" and "for" when predicting the next word. The attention mechanism thus introduced a new level of nuance to understanding language context, a major leap forward. Understanding the Attention Mechanism
There were two primary takeaways from the paper "Attention is all you need":
Attention to different words varies, highlighting the importance of each word in a sentence.
Positional Encoding is crucial to maintain the order of words, ensuring the model knows which words come before others.
A funny example of positional encoding is a sentence like "I feed my dog cat food." Without positional encoding, the model might think you're feeding your cat dog food!

Section 4: Birth of Generative Pretrained Transformers (GPT-2018)
The first Generative Pretrained Transformer (GPT) model was introduced by OpenAI in 2018. This model marked a shift in the NLP landscape. It was trained on a large corpus of text from the internet, and its main goal was to predict the next word in a sentence. The training process was unsupervised, meaning it learned patterns and predictions without explicit instruction.
Like its predecessor, the Transformer model, GPT used an attention mechanism. However, it expanded on this mechanism to consider all prior words in the generated text when predicting the next word. This new ability allowed GPT to generate coherent and contextually relevant sentences, making it a powerful tool for tasks such as text generation and completion. Understanding GPT

Section 5: The Evolution of GPT
In 2019, OpenAI released GPT-2. This updated model boasted an impressive 1.5 billion parameters, essentially making it a larger and more powerful version of its predecessor, GPT. The underlying architecture of GPT-2 remained largely the same, but it was trained on an even larger corpus of data, resulting in enhanced capabilities. Understanding GPT-2
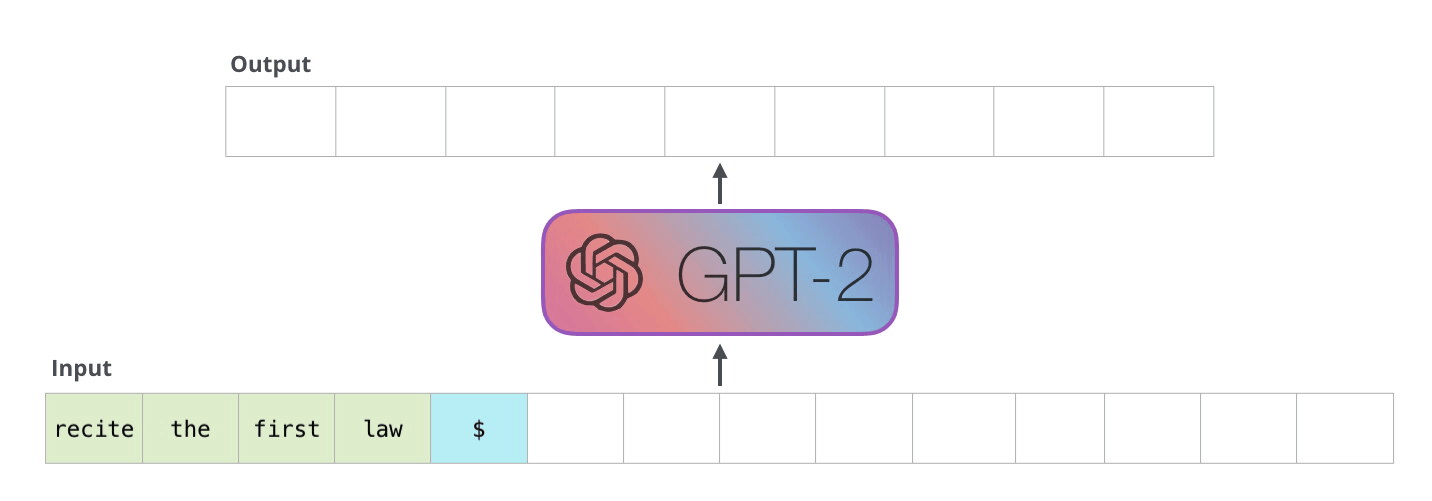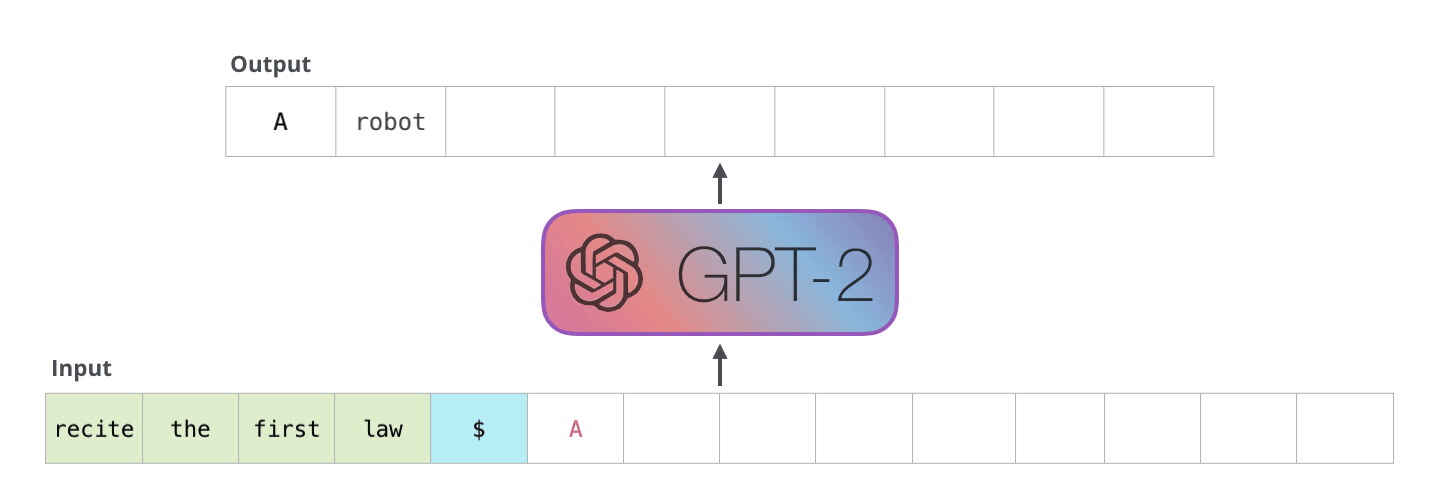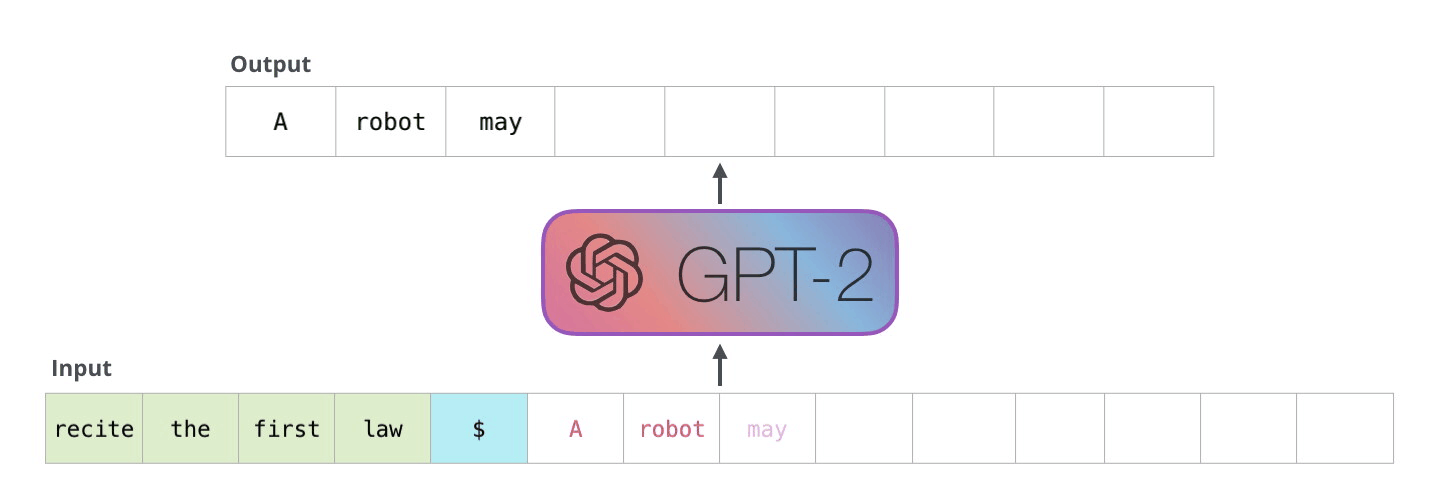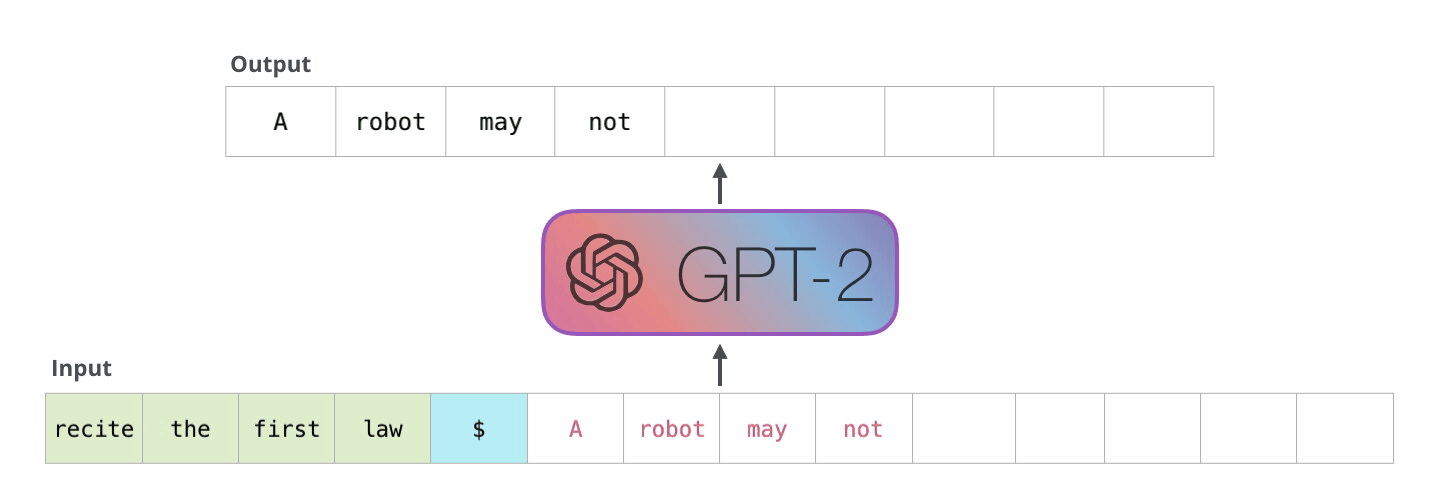
The following year, OpenAI took another significant step forward with the introduction of GPT-3 in 2020. With a staggering 175 billion parameters, GPT-3 was very powerful. Like GPT-2, GPT-3's architecture remains fundamentally the same, but its increased size allows for even more coherent and contextually accurate text generation. Understanding GPT-3
Section 6: Key Terminologies to Know and Why They Matter
When diving into the realm of LLMs, it's crucial to not only understand some key terminologies but also appreciate why they're important. Comprehending these concepts allows us to grasp the functionality, capabilities, and limitations of these models more deeply. Plus, it provides a solid foundation to engage with relevant literature and discussions in the community. Let's go through a few of these terms:
Parameters:
These are the parts of the model that are learned from historical training data. The number of parameters in the GPT series has grown astronomically, from 117 million in GPT to a whopping 175 billion in GPT-3. Understanding parameters helps us appreciate the complexity and capacity of these models, as well as the computational resources needed to train them.

Vocabulary Size:

This refers to the number of unique tokens the model knows, essentially its personal dictionary. The larger the vocabulary size, the more nuanced and varied the language the model can understand and generate. This knowledge provides insight into the linguistic versatility of a model and why certain models may generate more diverse or nuanced text than others.
Fine-tuning:
After a model is pre-trained on a large dataset, it can be fine-tuned on a more specific task, like translating English to French or writing poetry. Grasping this process enables us to understand how general-purpose LLMs can be adapted for specialized applications, providing immense versatility.
Fine-tuning is like going to medical school after graduating from college: you've got a broad base of knowledge, and now you're specializing.
Few-shot learning:
This is the model's ability to understand a task given only a few examples. This knowledge allows us to understand the model's capability to generalize from limited information - a vital aspect of its practical usability.

It's like showing a super-smart alien a few examples of a bicycle and then asking it to build one.
GPT-3's performance on few-shot learning tasks was a big part of what made it so exciting.
Context Length:
This refers to the amount of recent input that the model can "remember" or use to produce output. This is critical for understanding the model's ability to maintain a coherent context over extended conversations or documents.

It's kind of like having a conversation with Dory. After a few rounds of swimming, Dory forgets what you said. Similarly, the context length is the number of "laps" the model can "remember." The longer the context length, the better the model can keep track of long conversations or documents.
For instance, GPT-3 can pay attention to about 2048 tokens at a time. If we're talking about the English language, this is approximately a few pages of a book.
Anything beyond this limit, GPT-3 might start to lose track. It's a bit like your model has a short-term memory, and it can only keep so many pieces of information in mind at once.
But why do Terminologies Matter?
When you look at most research papers, you will come across the same set of terminologies, but they can carry deeper meanings if you don’t understand what they mean. Let us take these two models; LLAMa is known to perform better than GPT-3; why is that?

At first glance, LLAMa only has a 32,000 vocabulary size and 65B parameters as compared to GPT-3, but when you look closely, you realise it was trained on 1.4T tokens!

Section 7: Comparing LLMs to Human Brains
Language models and human brains, while similar in some ways, operate differently in many respects. Language models like GPT are trained to predict the next word in a sentence, relying solely on patterns found in the text data they've been trained on. They don't "understand" text in the way humans do and don't have emotions or consciousness.
On the other hand, the human brain is a multi-dimensional network processing emotions, visuals, sounds, tastes, and more. Our decisions and actions are based not only on logic but also on feelings and emotions. We learn from experiences and adapt over time, but we're also biased and can make mistakes.
Consider the question: "The population of India is "__" times the USA?". How does an LLM solve this problem compared to a human? (Inspired by State of GPT talk by Andrej Karpathy)
A Human would first:
Google the population of India
Google the population of the USA
Then divide it using a calculator
Then see if it sounds right.


LLMs will use tokens and a knowledge base to estimate the answer. However, they lack an internal monologue and won't do a sanity check or reflect on the question like humans would.

LLMs are remarkably good at generating human-like text, showing creativity, simplifying complex language, and translating between languages. However, they struggle with handling ambiguity, guaranteeing truthfulness, and recognizing and responding to emotional states.
Section 8: Playing Around with LLMs
After understanding the basics and the technicalities of LLMs, it's time for some hands-on experience. You can see the performance improvements and compare them yourself by exploring different models.
Here are a few demos that you can play with:
Salesforce CodeGen Model: This model is designed for code generation tasks. Salesforce has used the LLM architecture to provide an AI that aids in writing code. This can be a valuable tool for software developers. You can check it out here.
GPT-2 Model: GPT-2, an earlier version of GPT-3, was OpenAI's first attempt at a large-scale transformer-based language model. Despite its smaller size compared to GPT-3, it is impressively capable. You can play around with it here.
Cohere: Cohere is another LLM that you can experiment with. You can compare its performance with other models to see the differences and improvements. Check it out here.
After experimenting with these models, you will gain a better understanding of how LLMs work and how different models compare in terms of performance and capabilities. The hands-on experience will help reinforce the concepts we've been discussing in this series.
What's Coming Up Next?
For the next edition of this newsletter, we're going to take a deep dive into the LLM pipeline. We'll explore the two crucial steps involved in training LLMs: Pretraining and Finetuning. Understanding these stages is vital for anyone keen to utilize these technologies to their fullest extent.
Moreover, we'll also provide a guide on how to fine-tune your own LLMs. This will provide you with practical knowledge and experience, allowing you to customize an LLM for your specific tasks or projects.
Remember, the goal of this series is to provide you with both a theoretical understanding and practical skills in working with Large Language Models. As we advance through this journey, we hope to demystify this incredible technology, making it more accessible and beneficial for all.
Thank you once again for your time, and we look forward to continuing this exploration with you in our upcoming newsletters.