
MLOps for Research Labs
A simple MLOps architecture for research ML workflows enhancing reproducibility, experimentation, and collaboration

MLOps standards set in the industry may often be too complex and expensive for research labs focussing on building novel techniques instead of deploying them at scale. However, MLOps standards and best practices can still help research labs by streamlining processes, ensuring reproducibility and facilitating experimentation and collaboration. This blog proposes a simple MLOps architecture that research labs can adopt.
Why do research labs need different MLOps?

Scale and Complexity
MLOps is designed to handle the needs of systems serving millions of customers and generating significant revenue. In contrast, research labs often operate on a smaller scale, focusing on experimentation and model development. The MLOps requirements for a small lab team can vastly differ from large-scale companies. Even small-scale companies implementing reasonable scale MLOps are too large for a small lab team.
Limited Compute Resources
Research labs typically have less access to extensive model training compute resources than companies. They often rely on a university's High-Performance Computing (HPC) system or even a PC for their research needs. As a result, research labs require MLOps solutions that can efficiently utilize the available resources without compromising the quality of their work.
Deployment is Not the Primary Focus
While companies emphasize deploying machine learning models into production, research labs prioritize the training and experimentation aspect of the process. Researchers aim to improve model performance, understand the underlying principles, and innovate in their respective fields. Consequently, research labs need MLOps that cater to their specific focus on training and experimentation rather than deployment.
What are the constraints of a research lab?
Minimizing Engineering Overhead
Researchers typically prefer to focus on model building and experimentation rather than the engineering aspects of machine learning unless that is their specific research area. To accommodate this preference, MLOps solutions for research labs should be easy to set up, use, and debug. Ideally, the system should operate autonomously without requiring significant time for maintenance.
Maintaining Flow and Experimentation
MLOps solutions should not be a bottleneck for researchers, as this could disrupt their flow state and impede the experimentation mentality crucial for research. To avoid this, MLOps tools should be designed with the researcher's workflow in mind, streamlining the process and enabling seamless integration into their daily work. The MLOps solution should help researchers track their previous results and build on top of it.
Cost-Effective Solutions
Research labs often operate with limited budgets, so MLOps solutions must be cheap and, ideally, free. Leveraging open-source tools can minimize costs while providing powerful research functionalities.
Data Security and Ownership
Research data can be private, confidential, or sensitive, so MLOps solutions must ensure data security. Ideally, researchers should retain data ownership, and MLOps tools should provide robust access controls and data management capabilities to safeguard information.
Efficient Resource Management
Since research labs may have limited access to compute resources, such as a single HPC system, MLOps solutions should provide efficient ways to queue jobs and assign priorities to different tasks. This will help researchers make the most of the available resources while minimizing the impact of resource constraints on their work.
What are the priorities of research labs?
Model Management and Versioning
Effective model management is crucial for research labs. Researchers should have access to past trained models, along with the parameters and data used for training. Tools like MLflow can help track and manage different model versions, ensuring that researchers can easily compare and analyze their work.
Reproducibility and Hyperparameter Tracking
Reproducibility is a critical aspect of research. Researchers should be able to track the hyperparameters used to train their models, ensuring that experiments can be reliably reproduced. This is essential for validating research findings and building on previous work.
Data Source and Versioning
Accurate data sources and version tracking are vital when publishing research papers. Tools like DVC (Data Version Control) can help researchers manage data sources and versions, ensuring that the data used in a particular work is correctly identified and documented.
Easy Iteration and Experiment Tracking
MLOps solutions should enable easy iteration and tracking of experiments, including data, hyperparameters, and results. This includes metadata about the experiments, query and filter results, and visualize training results in a dashboard format.
Sharing and Collaboration
Research labs need MLOps tools that facilitate sharing and collaboration. This includes sharing code through platforms like GitHub, publishing research papers, and writing blog posts. Less than 30% of researchers currently share their code, and MLOps can help improve this by making it easier to share work.
Balancing Automation and Complexity
While automation and continuous integration/continuous deployment (CI/CD) can be beneficial, they can also add complexity to the research process. MLOps solutions should strike a balance between automation and simplicity, avoiding unnecessary complexity that could detract from research efforts.
A sample architecture for MLOps at a research lab
The research lab workflow

To design an effective MLOps architecture for research labs, it's crucial to understand the typical research project workflow. In this blog section, we will outline the research lab workflow and propose a generic MLOps architecture based on those requirements.
The first step involves gathering and analyzing data. The data is cleaned and preprocessed for model training. It's essential to version the data and track the preprocessing steps at each stage for reproducibility. As the project progresses, researchers may apply different preprocessing techniques, generating alternative data versions, which should also be tracked.
Once the data is prepared, researchers create and train their model architecture. Tracking model hyperparameters, model files, and key statistics throughout the process is essential. Additionally, each training run should be tagged with the data version used.
After training, researchers visualize and analyze the results. If the outcomes are unsatisfactory, they may iterate by modifying the model or further processing the data.
When sharing preliminary or final results, tracing all the steps used to create those outcomes is vital. This includes the data version, preprocessing steps, model files, training parameters, and all analyses and results. The failed attempts and experiments that led to the final model are often shared and need to be easily retrievable.
Researchers may sometimes want to deploy their model as a demo. This process should involve fetching the model files from the model store and deploying them to a suitable platform.
Generic MLOps Architecture for Research Labs

Based on the above workflow, here is the proposed MLOps architecture. In the middle, we have an HPC where researchers can submit training jobs. The HPC should be able to fetch data from the data store. Researchers can clean and process data and store it in the data store. The data that is used for a training run should be versioned in the data store, and the data version should be tagged with the training run. After training, the model files and all training metadata and artifacts should be stored in the result store. Researchers can access this store to analyze results. Optionally you can have a front end where training results can be visualized, and if the model is deployed, this front end can also display results from the mode.
An Example Architecture Using Popular Tools
Here is a sample implementation of the above architecture with some popular tools.
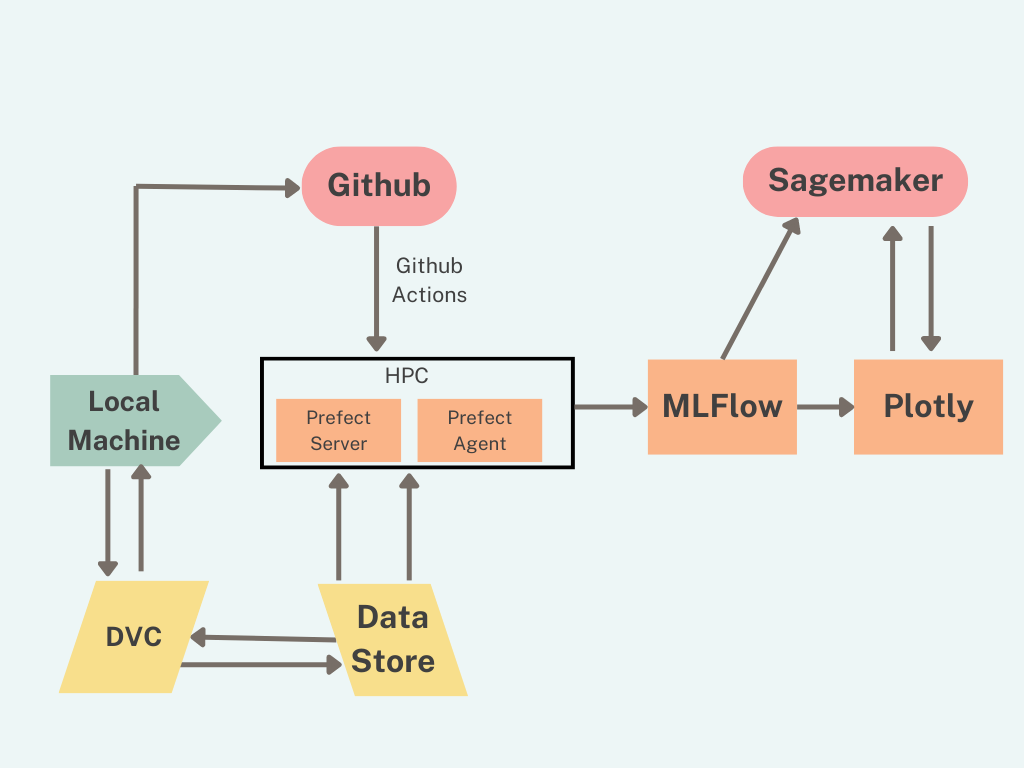
DVC is used for versioning data
Prefect is used for orchestrating tasks running on the HPC
Jobs can be submitted to the HPC using GitHub Actions
Training jobs can write their result to MLFlow. MLFlow tracks not only the experiment metadata but also acts as a model registry
MLFlow can also deploy models to SageMaker or other deployment platforms
Plotly can be used to display the results of model training and it can also query models in SageMaker to show results
Below are the list of tools and what they are used for. I have also suggested alternative tools you can use:
Data labelling: LabelStudio, CVAT
Data versioning: DVC
Feature Store: Feast
Model and experiment versioning and tracking: MLFlow, DVC
Code Repository and Pipelines: GitHub and GitHub Actions
Orchestration: Prefect, MetaFlow
Result Visualization: Plotly, StreamLit, GitHub Pages
Model Deployment: AWS SageMaker, AzureML, Vertex AI