
Steering Activations, Not Pipelines
A look at representation engineering as a lightweight alternative for controlling model behavior.


In our last post, we analyzed a systems-thinking approach to reliability: building a robust, external pipeline to manage an LLM. It’s a classic engineering solution—treat the model as a component and build guardrails around it.
But what if you could just... fix the model’s behavior directly?
This month, we’re also featuring an important methodology from Ayesha Imran, an Open Source Researcher at EleutherAI and an Associate Software Engineer at Data Science Dojo, who specializes in this exact problem. As part of EleutherAI’s SOAR program, she is exploring a radically different, model-centric method.

The pipeline approach we just looked at is a classic example of systems thinking. You treat the LLM as a component, a powerful but unreliable one, and you build a robust system of checks and balances around it. This is a proven, reliable, and understandable way to build production-grade software.
But there is another, more new-school approach that is gaining traction. Instead of building a system around the model, this method attempts to go inside it. This is the field of representation engineering, and it’s less about pipelines and more about a single, fundamental question:
What if you could find the “lie” button inside the LLM’s brain and... turn it down?
This is precisely the path that we decided to explore.
“Persona Vectors”
To understand this, you need a simple mental model for how an LLM “thinks.”
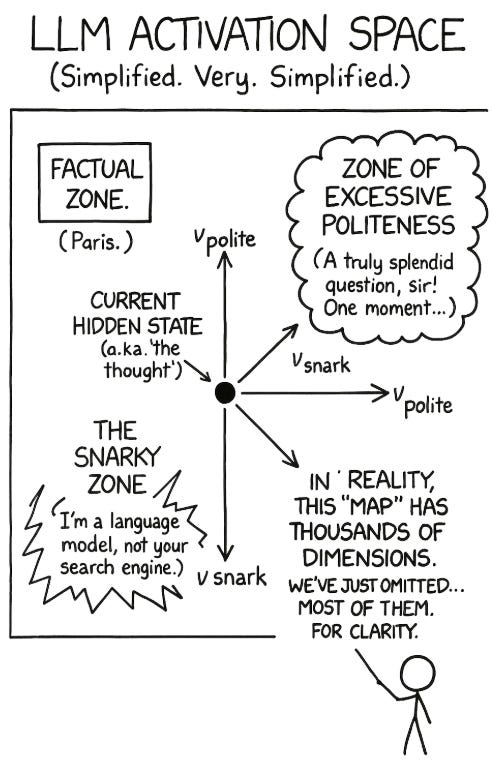
The “Brain” as a Map: Think of an LLM’s internal state: its “brain”, as a giant, multi-dimensional map. As it processes a prompt and prepares to generate the next word, its “thought” is a single point on that map. This point is its hidden state or activation.
“Vectors” as Directions: A “vector” is just a direction on that map. A step in one direction might lead to “polite” answers. A step in another might lead to “angry” answers.
The Anthropic paper, “Persona Vectors,” found that you can reliably find these directions. By contrasting the model’s internal states when prompted to be, say, “polite” versus “rude,” you can isolate the specific vector, the direction on the map, that corresponds to “politeness”.
Finding the “Hallucination Vector”
The researcher’s key insight was to apply this same logic to a more abstract trait: hallucination.
If you can find a vector for “politeness,” why not one for “factuality”? Or, more to the point, why not find the specific direction that corresponds to the model making things up?
If you could isolate this “hallucination vector,” you wouldn’t need a complex external pipeline to catch lies after they’re told. You could, at the moment of generation, simply “steer” the model away from that direction on the map.
This leads to an architecture that is radically different—and far lighter—than the multi-stage pipeline.
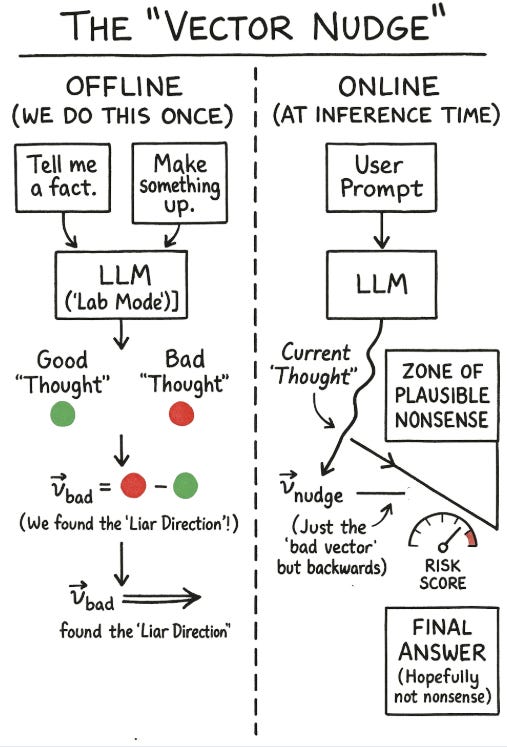
Step 1 (Offline): Find the Vector. This is a one-time research task. You force the model to generate both factual and non-factual answers and then analyze its internal activations to find the differential “hallucination vector.”
Step 2 (At Inference): Get a Risk Score. When a new user prompt comes in, the model processes it. At the last layer, before it generates a word, you take its hidden state and project it onto your “hallucination vector”. This gives you a simple number, a “risk score,” that predicts the likelihood of a hallucination.
Step 3 (At Inference): Intervene or Pass. You set a simple threshold.
If Risk is Low: Do nothing. Let the model generate its answer as usual. This is the key to efficiency.
If Risk is High: Apply the “steering.” You actively modify the model’s hidden state, nudging it slightly in the opposite direction of the hallucination vector before it generates the token.
The goal is to create a lightweight guardrail that adds almost no computational overhead or latency, unlike a heavy pipeline that might require multiple extra API calls.
The Fundamental Trade-off: Efficiency vs. Fragility
This approach is elegant and computationally cheap, but it comes with its own set of engineering trade-offs.
The Pipeline (Approach #1):
Pros: Robust, explicit, and easy to debug. If a stage fails, you know which one. It’s a system you can understand and trust.
Cons: High cost. Every stage adds latency and token usage.
Vector Steering (Approach #2):
Pros: Extremely lightweight and fast. It’s a minor mathematical adjustment at inference time, not a series of new API calls.
Cons: Potentially fragile and “magical.” Does the “hallucination vector” for one domain (e.g., history) work for another (e.g., medicine)? Does it work for all models? This is deep, cutting-edge work, and it’s much harder to debug if it fails.
What’s Next
This is just the beginning of this research sprint. The architecture is designed; the next phase is rigorous experimentation to see how well it performs in practice.
We’re looking forward to sharing the quantitative results of this work in a future post. Stay tuned.
 | A guest post by
|