
Task-Specific Models are the New Frontier

For the past two years, the default enterprise AI strategy has been the same everywhere. Pick a large general purpose language model, write better prompts, and layer retrieval augmented generation on top.
Teams spent quarters on this, they built pipelines, ran evals, hired ML engineers to close the gap. Performance improved and then plateaued. The ceiling they kept hitting was not an implementation problem. It was a structural one and no amount of prompt engineering changes what a model was built to optimize for.
Today the leading AI companies are building and deploying specialized models for their most critical, high volume workflows.
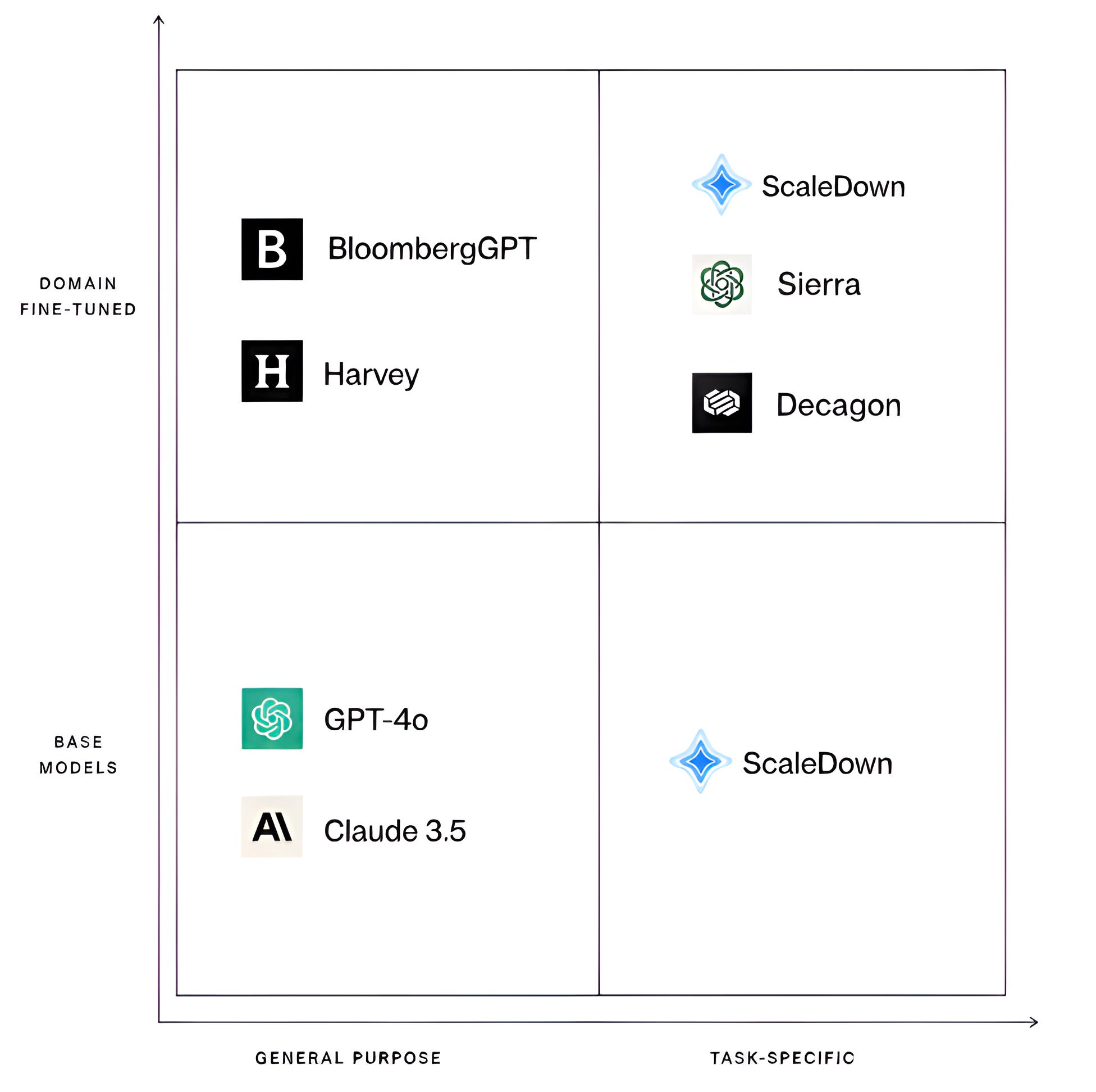
The Only Model Matrix That Matters.
There are two base model types. One is general purpose models that handles any task. They write code, transcribe speech, answer questions. A jack of all trades, but a master of none.
Another is task-specific models, they do one particular action extremely well. A model built for classification is not the same as one built for summarization. The training data, architecture, and evaluation criteria are all oriented around mastering a single capability.
Both types can be fine-tuned to a domain. This gives you four combinations but only one of them compounds.
You Can Make It Less Wrong, But You Cannot Make It Precise.
Most enterprises today are stuck on general purpose models and the most AI forward are fine-tuning to close a gap it was never going to close. Sierra and Decagon are two of the few leading AI native companies that made it to the fourth by building their own task-specific models, fine-tuned to their domain.
The ceiling exists for general purpose models because the foundation was wrong. A model built to do everything cannot be fine-tuned into a model built to do one thing extremely well. You can add domain knowledge on top to make it less wrong but you cannot change what the model was built to optimize for and you cannot make it precise.
The right sequence is the opposite. Start with a specific model built from the ground up for the task. Then fine-tune that model on your domain data. The task-specific foundation ensures precision and the domain fine-tuning ensures relevance. Together they produce something that neither path achieves alone.
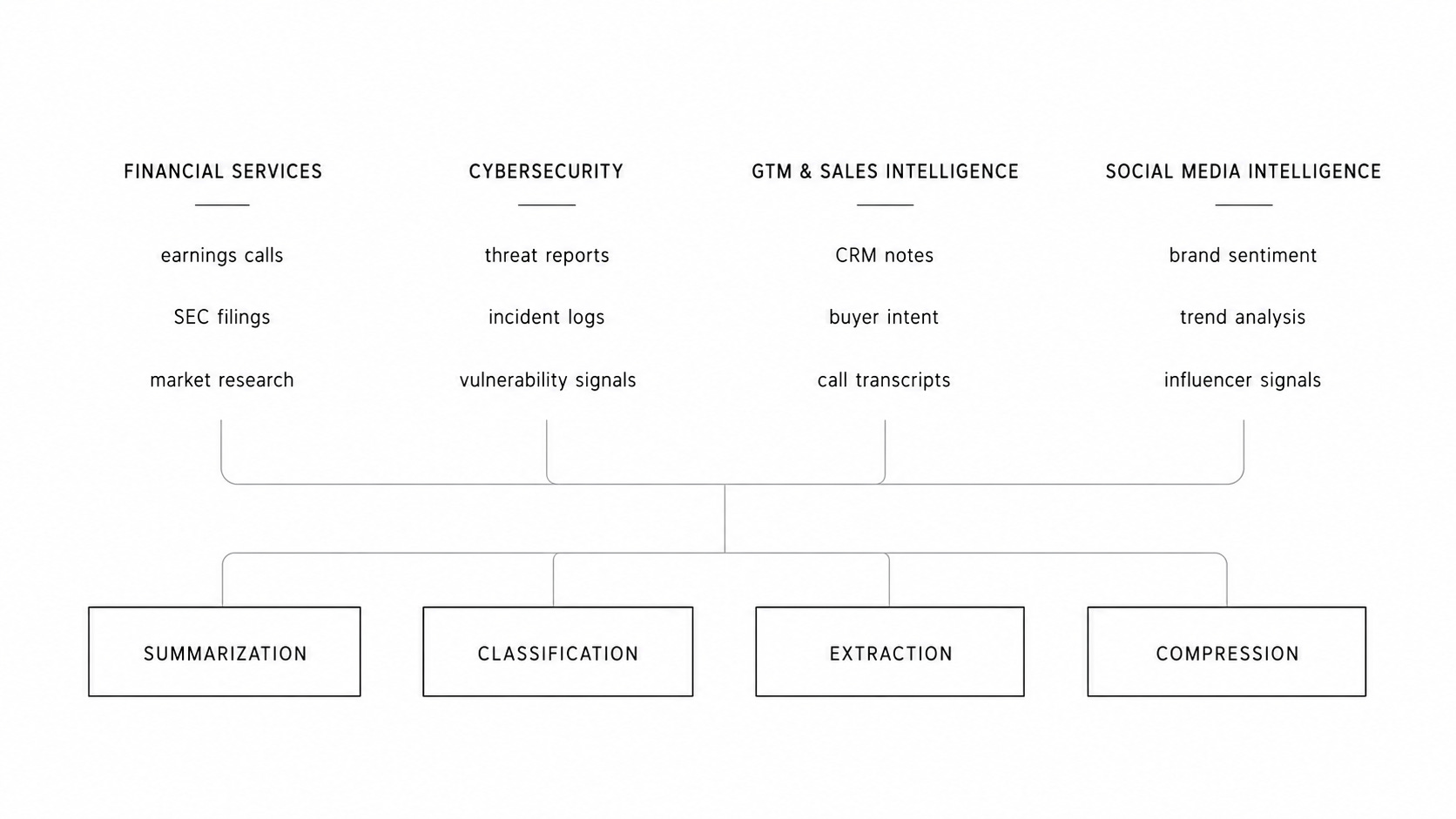
For all of these verticals, the core tasks stay the same. It’s about summarizing what matters, classifying what it means, or extracting what is actionable. Although the domain may be different, the type of tasks stays the same.
Renting vs Owning Intelligence
If your AI infrastructure is built entirely on closed sourced general purpose models, you are renting intelligence. You are prompt engineering on top of someone else’s foundation and getting better at using a tool you will never own.
You can’t do serious post-training on a closed model or even run meaningful reinforcement learning on top of an API. The foundation has to be yours or you are compounding someone else’s asset instead.
Open Source Doesn’t Solve the Objective Mismatch
The common workaround is to reach for an open source general purpose model and fine-tune it on domain data. It feels like a solution where you own the weights, you control the training, and it is cheaper than paying for API calls.
The problem is the same one. You are still starting from a general foundation built to do everything. Open source does not change what the model was optimized for. Fine-tune a general purpose model on security signals and you get to roughly 30% on tool calling benchmarks. A model built specifically for that task gets to 77%. You can keep fine-tuning, and it will keep improving, but the ceiling is the same. The model was not trained to classify threat signals but trained to predict the next token across the entire internet and these are not the same objective.
Fine-tuning is able to solve superficial problems but fails to solve the underlying problem of the objective mismatch between general models and task-specific ones.
The Gap That Widens Every Quarter
Organizations that control their model foundation improve it continuously. Every new data point, every edge case, every domain-specific signal becomes training material for a model that gets better over time. Closed APIs lead to a standstill since access to the model is limited. On the other hand, organizations that pulled a general purpose model off Hugging Face can fine-tune it but they are still working from the wrong foundation. The accuracy and quality ceiling does not move no matter how much you fine-tune a general purpose base model. The secret is switching to task-specific models, as those are the only type that actually compounds.
The performance gap is already measurable. In high-volume classification workloads, task-specific models are already outperforming larger general-purpose models on the exact tasks they were built for while operating at a fraction of the compute cost. In our classification benchmark, ScaleDown’s Classify model achieved higher accuracy than GPT-5.4 Mini and Nano while being roughly 200x cheaper than Mini and 50x cheaper than Nano.
This matters in systems that process massive streams of real-time information. A real-time threat intelligence platform, for example, ingests millions of public signals every day. Every piece of content must be classified as signal or noise. ScaleDown’s classification SLM hits 90.53% accuracy at 200x lower cost than GPT-5.4 Mini. The entities get extracted and the analyst gets a summary. ScaleDown’s summarization SLM costs $7.20/day at 10,000 summaries versus $58/day for GPT-4.1 Mini, with a quality gap human evaluators cannot distinguish.
AI-native companies like Sierra and Decagon identified which tasks matter most to their business and built the model that runs them. The companies still on general purpose models, especially closed source, are renting that advantage from someone else who is in control.
General purpose models got enterprise AI started but 95% of enterprise AI pilots have failed to deliver measurable results whereas task-specific, domain fine-tuned models are what will make it actually good. The organizations that recognize this now will have a model stack that is not just more accurate today but harder to close in on every quarter that passes.
The model stack is fixable, but the fix is not a bigger model. The solution is a more precise model, built for the task, tuned for the domain, and owned by the organization that needs it most.
We offer 50M free tokens for every agent. Try it at scaledown.ai.