
The Economics of Building ML Products in the LLM Era
LLM APIs will fundamentally change how AI products are developed and who can develop them

I have been training and deploying LLM-based products for the last few years. The advent of multi-modal Large Language Models with emergent abilities fundamentally shifts how AI-based products will be trained, built and deployed. In this article, I want to share my thoughts on how LLMs and LLM APIs have altered the lifecycle and economics of building AI products.
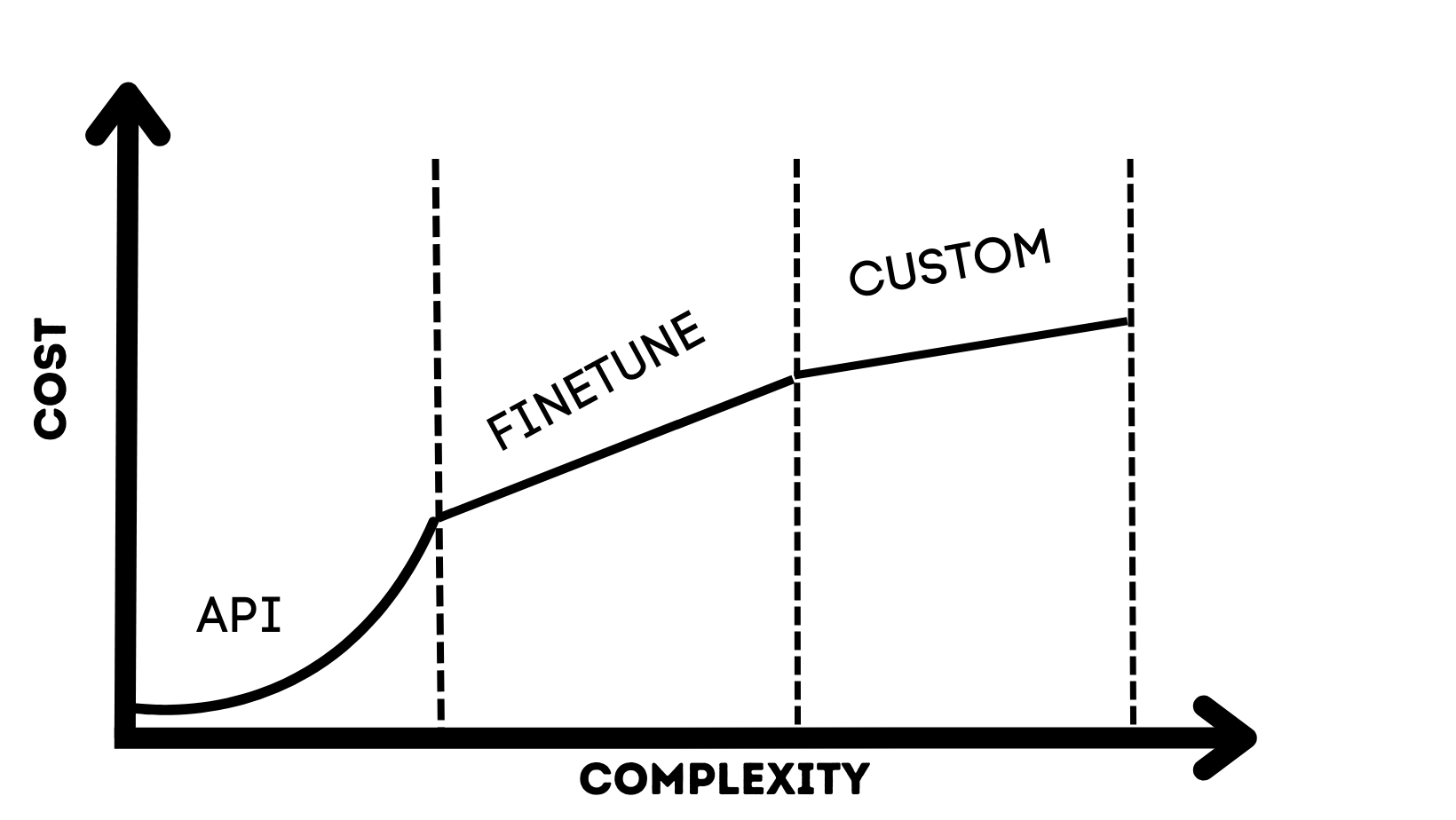
The graph above shows the cost of deploying an LLM product in the y-axis. Here I am considering technical costs related to the LLM product: model endpoints, model training, and engineer salaries. The x-axis shows increasing complexity. I am using complexity as a broad term for everything that happens as an ML product matures and grows. The main things that happen are an increase in the load, the number of models the product has, the amount of data being generated and the chaining of models to do complex tasks.
The plot is divided into three parts: API, finetune and custom. These are the three stages an ML product will go through in its lifecycle as it matures. Whether it is the first product a startup builds or a new application in a tech giant, the lifecycle will be very similar2.
API
Companies will directly start building applications using APIs first. It allows companies to build proof-of-concept applications and get them to market quickly, giving them a competitive advantage.
Data was a significant barrier to building machine learning applications. You were either an incumbent with lots of data or rely on public data to build proof-of-concept applications. For the latter, this process was time-consuming and expensive. Your deployed application was usually no good, and it usually required humans in the loop to fix errors and collect training data. This “cold-start” problem is no longer the case.
Another advantage of APIs is that building applications are now more accessible. You don't need to hire data scientists to create simple prompts and call APIs. The prompts can be finetuned by subject matter experts, product managers, or even engineers.
This is where the graph starts; costs are meagre. Companies can now build applications faster with little to no data. The barrier to entry is very low.
While the costs are low initially, they can quickly grow as the application becomes complex and more people start using it. The growing number of prompts and longer prompts can cause an exponential increase in API costs.
At this point, latency can be an issue. You are at the mercy of the availability and demand that the API is facing. Will your result come in 1 second or 1 minute? You don't know. As your product grows, the latency and costs will worsen with more applications and chained prompts. You are also now starting to get serious customers. How do you manage hallucinations? How do you manage data security? Can you trust that the completion tokens don't contain irrelevant responses?
Despite all these challenges, your accuracy is still pretty much the same as when you started. You don’t even have control to improve the accuracy. Your load has exponentially increased your costs and made your product unsustainable to keep running. You must now finetune the model and deploy it on your servers.
Finetune
If you were good at forecasting your growth and costs, you would have started the process of finetuning your own model at least six months before your costs ballooned out of control. At this point in your product’s lifecycle, you have lots of data to finetune a base LLM.
Finetuning has several advantages. Firstly, your accuracy increases. You can also perform pruning, quantization or distillation to reduce the size of your model. This should reduce hallucinations and make your generated outputs more predictable.
Another advantage of finetuning is that you can deploy the model on your servers. This will give you the most cost savings and increase trust in the system among your clients. You can also make your prompts more expressive and not have to worry about the length of the outputs since your hosting cost doesn't depend on the number of tokens. As your load and application complexity increase, you will have to spin up more resources, but the cost will not increase exponentially.
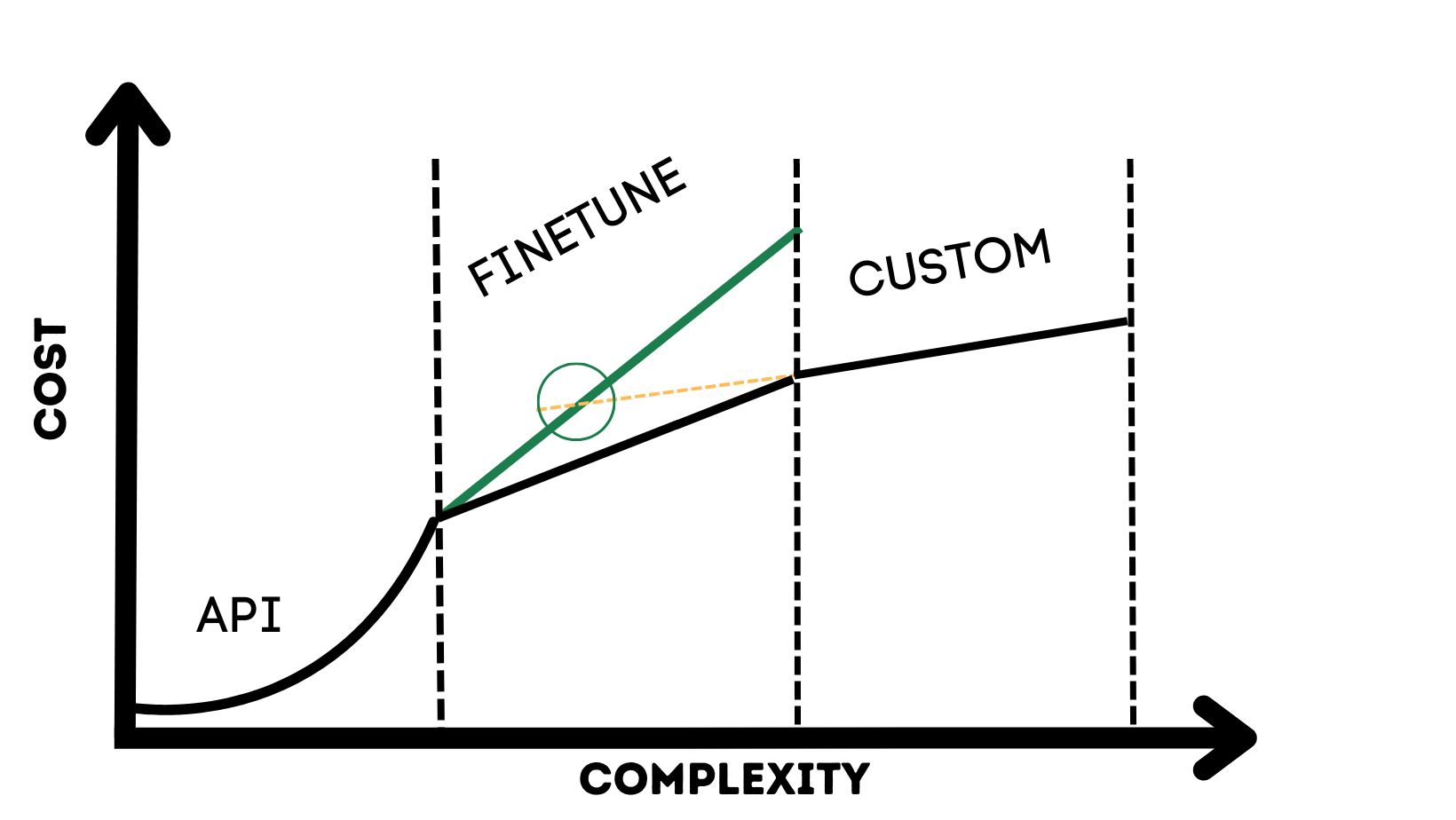
There is an initial model training cost, which will be recurrent if your data tends to shift significantly, but it will still be cheaper in the long run. Many companies also provide easy APIs to finetune their models, and you don't need to hire a team of data scientists to do so. You might even get by with an intern.
However, there is a caveat here. If you are using someone else to host the finetuned LLM, your costs will be much higher than if you were hosting the model yourself. The green line in the graph represents this. In this case, you would have to move to the next stage much faster.
This will be the end state for most applications, especially those with moderate load. The need to optimize the models further or even train and build custom models will be far outweighed by the need to build new applications and models.
Custom
You are now the incumbent. Your product has been on the market for multiple years. You have a massive amount of training data. So why would you want to train a custom system?
One of the main reasons why you may want to train a custom model is to reduce your hosting costs. As your application grows and your load increases, running large language models at any reasonable latency will require your endpoints to have GPUs, which can be costly. By removing your dependency on GPUs and using a custom model with fewer parameters, you can reduce your costs by 4-10x and improve latency.
Of course, building a custom model is not a simple task. You must hire a dedicated data science team to train and deploy the models. Depending on the complexity of your system, it could take several years to reach similar accuracies as your current model. The best way to start is by migrating small applications or functionalities to a custom model and gradually building from there.
This will be a challenging process, as you may have a single language model that performs multiple functions that are not possible for a custom model to do. However, with the data and resources your product has accumulated, you can set up your data science team for success and work towards building a more efficient and cost-effective system.
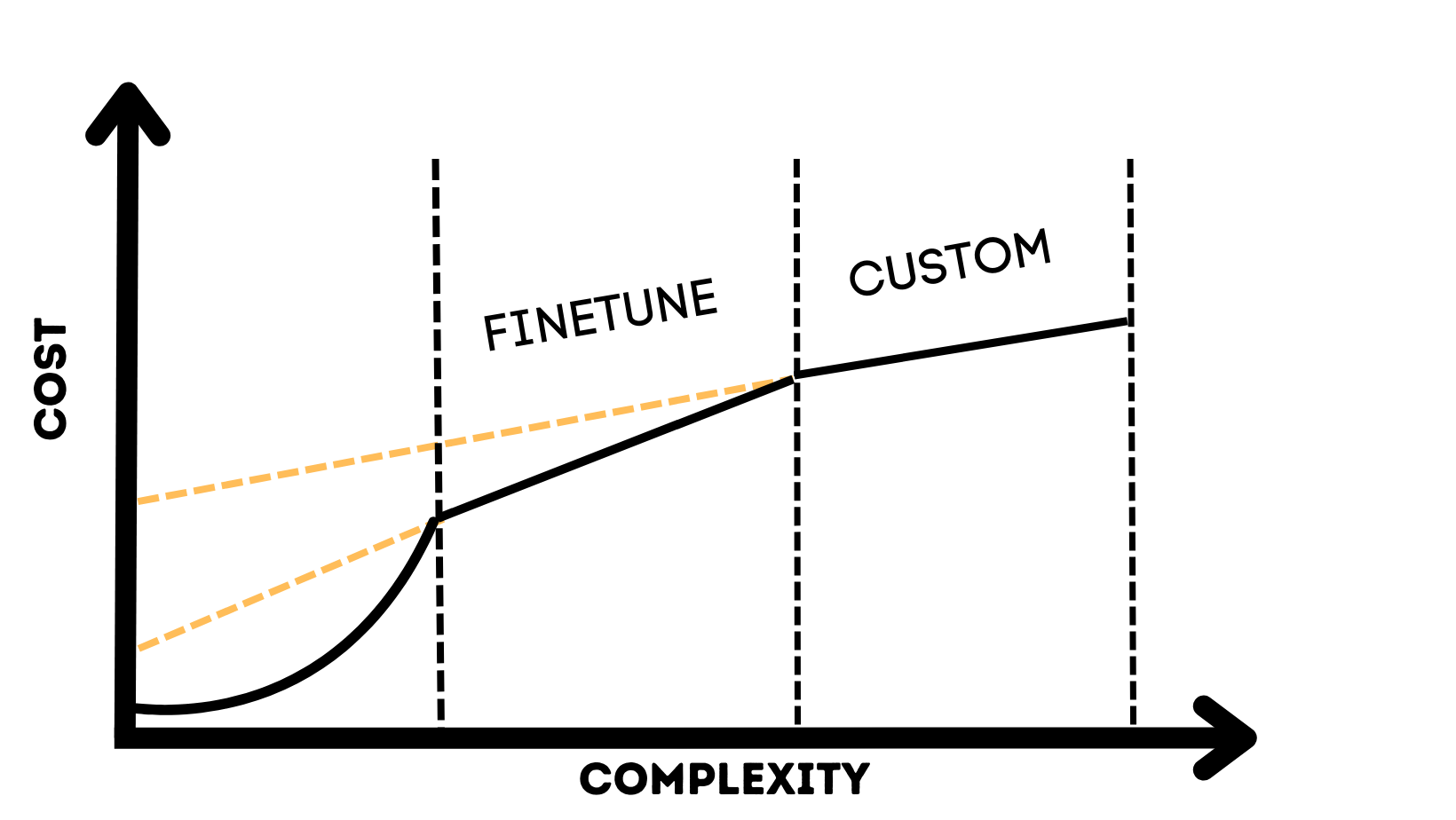
Why not finetune from the start?
So why not skip the API step and start finetuning a model? After all, we will still have to finetune or build a custom model eventually.
One significant factor to consider is the upfront costs. If you skip the API step and start finetuning a model, you will need to invest in R&D, which includes hiring a team of data scientists. This is not cheap and may not be feasible for smaller companies with limited resources.
Another cost to consider is the data penalty. If you do not have readily available training data, you must start collecting data, which can be time-consuming. This is known as the cold start problem, and it can be a significant barrier to entry for many companies.
Skipping the API step is also risky. You don't know if a custom architecture will be able to reach reasonable accuracy levels. Even if it can, you don't know how long it will take to build a model good enough to deploy. This can significantly waste time and resources if the final model does not meet the desired accuracy level.
This is the most significant advantage of using LLM APIs. You can now quickly validate your idea and build a capable MVP with minimal effort. They make it much easier for smaller companies and startups to enter the market without making substantial investments in R&D or data collection. It removes the barrier to entry that only startups with funding or teams with access to private data sources could cross. Solving this cold start problem is one of the most significant contributions that LLM API companies are playing in the economics of building machine learning products.
Appendix
The above arguments are entirely irrelevant for non-LLM based products. However, non-LLM products will not be able to compete with LLM-based products unless the application is very niche. LLMs may be overkill in some particular, low-latency, tiny applications. In some industries, LLMs may never even be deployed (Banking will probably be one of them).
In some companies (especially larger companies), the early stages of the lifecycle will only serve as a baseline and never be deployed due to trust, governance, ethics and legal issues.
I believe the above points are valid for both real-time and batched systems. Due to the added latency and throughput constraints, the problems will creep up on you faster in a real-time system.