
The Rise of RAGaaS: RAG as a Service
Forget vendor-wiring and broken dependencies-Why RAGaaS might just be what you are looking for?

I remember a particular project where I attempted to connect RAGAs, a RAG evaluation framework, with LangChain for a RAG project I was working on. I followed the documentation diligently.
To my frustration, their sample code didn't work. Their API was different from what was mentioned in their documentation.
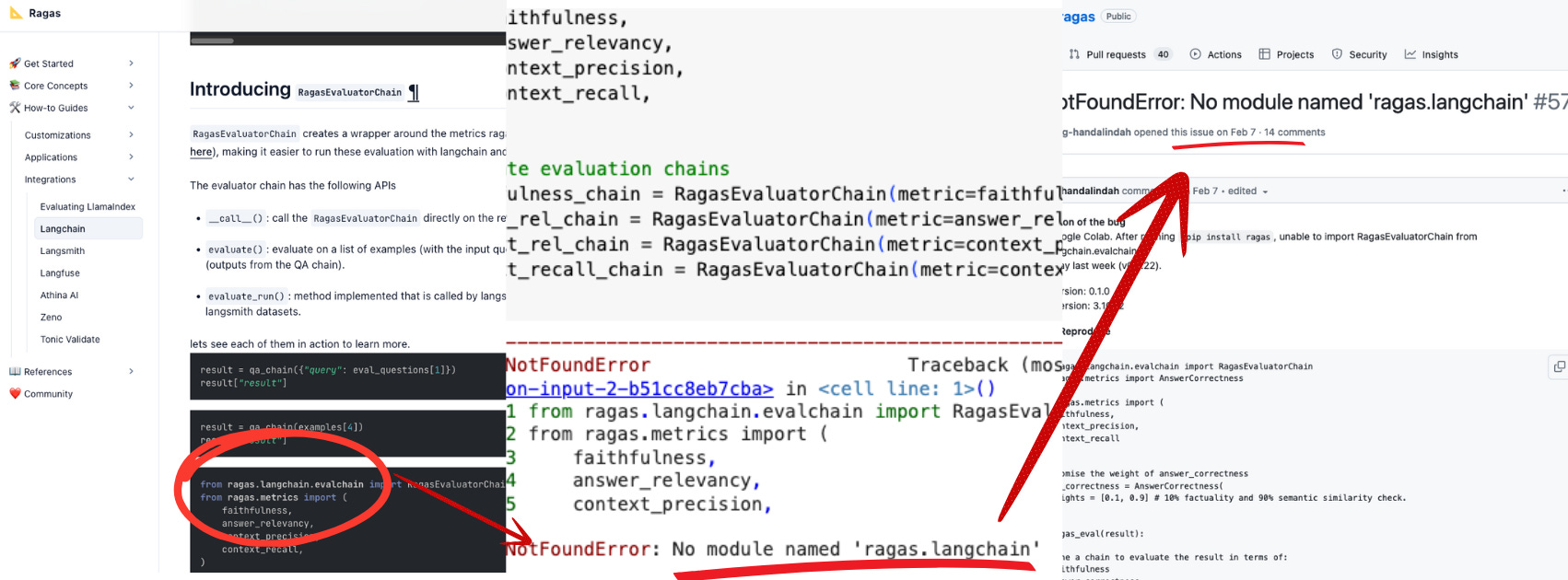
Such discrepancies are frustrating and time-consuming. As developers, we need to spend time debugging many obscure packages with little support or documentation. This experience made me step back and realize the broader complexities that had evolved in the RAG landscape.
Evolution of RAG
Initially, RAG systems were monolithic, relying on a single LLM. These standalone models were straightforward to manage, but the need for real-time, relevant information drove their evolution.

As the need for more relevant and up-to-date information grew, the first evolutionary step in RAG emerged: the introduction of vector databases. These databases, such as Pinecone or Qdrant, dynamically augmented the LLMs' knowledge with relevant context from external sources. Developers now had to manage the LLM, the integration with vector databases, and the data ingestion pipeline to keep the data relevant. This required additional skills, time, and resources.

The complexity didn't stop there. The next leap involved incorporating structured databases and knowledge graphs, enabling RAG systems to reason over structured and unstructured data. This added more layers of management, as each data source came with its own APIs, query languages, and connection protocols.
Today, a typical RAG application consists of a complex web of interconnected components spread across multiple platforms and vendors. Developers must navigate a myriad of APIs, data formats, and integration points to ensure seamless communication and data flow between these components. Each component requires specialized management, leading to increased development time, higher maintenance costs, and a higher risk of compatibility issues and performance bottlenecks.
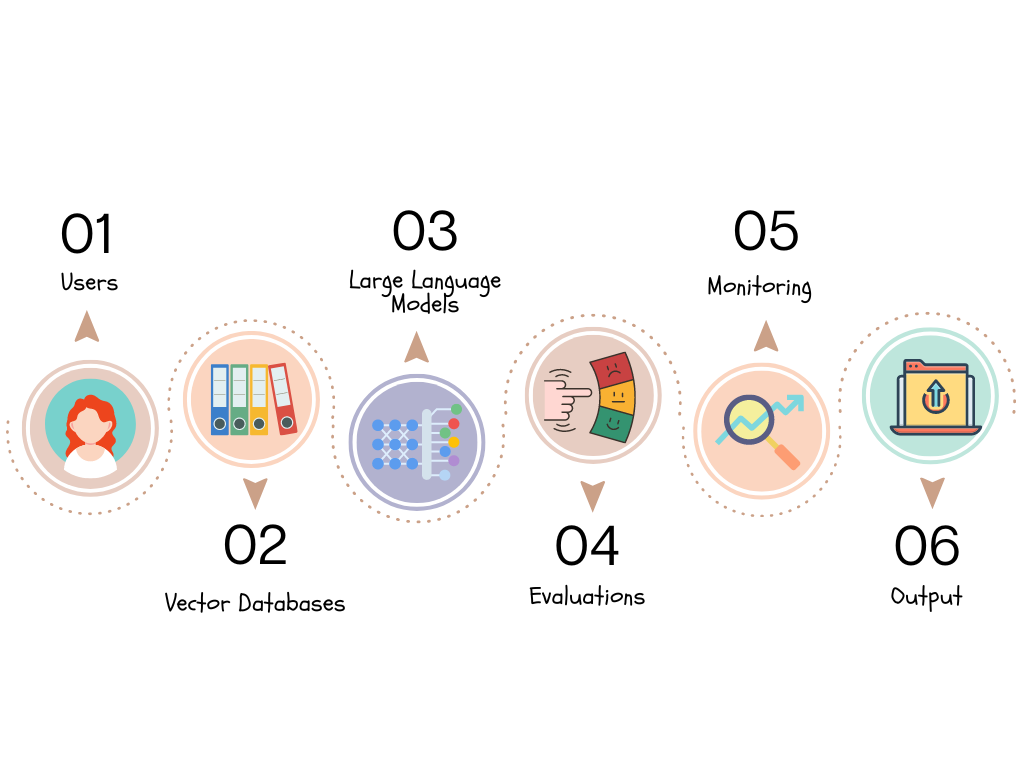
Moreover, the distributed nature of modern RAG applications has introduced new challenges in areas such as security, scalability, and fault tolerance. Ensuring consistent access controls, data encryption, and compliance across multiple components and platforms is daunting. Updating individual components or integrating new tools and LLMs without affecting the overall performance of the RAG application requires careful orchestration and monitoring.
The Complexities of RAG

Many open-source packages, such as LangChain, LlamaIndex, and HayStack, are available, but they often come with complexities. Their APIs can drastically differ from what is documented, leading to integration challenges and increased development time as engineers struggle to reconcile the documented functionality with the actual implementation.
Moreover, each component has its dependencies, configurations, and performance characteristics. Ensuring that these components work together harmoniously requires meticulous planning and extensive testing.
Relying on multiple vendors and open-source projects can lead to vendor lock-in and system fragmentation. Each vendor’s solution might have limitations, licensing restrictions, and support challenges. Managing these dependencies and ensuring a cohesive integration further complicates the development process.
A production-grade RAG system must continuously evolve to improve performance. This not only involves integrating user feedback but also updating models and using the latest tools and techniques. Implementing a feedback loop and continuous improvement pipeline adds another layer of complexity to building RAG systems.
Simply put, creating an efficient and effective RAG system demands deep expertise in AI, NLP, data engineering, and software development. However, finding and retaining talent with such specialized skills can be challenging. This expertise gap often hinders teams from successfully implementing and maintaining a RAG system. Eventually, most RAG applications fail and we are now starting to see companies reversing course on their AI ambitions.
The Rise of RAGaaS (RAG as a Service)
Building a RAG architecture requires a substantial investment in both time and expertise. Many teams do not have the luxury of dedicating months to integrating and fine-tuning various components while also managing their core business operations.
Given these complexities, we are now witnessing the emergence of a new type of solution: RAG as a Service (RAGaaS). RAGaaS providers offer fully managed services that handle all aspects of the RAG architecture. These end-to-end services address the challenges of building and maintaining a RAG system, allowing development teams to focus on their core application logic and business goals.

Several companies are leading the charge in the RAGaaS space, offering solutions that address the complexities of building RAG systems. A notable provider includes Graphlit.
RAG tools can be broadly classified based on their scope and integration complexity.
Vector databases have a single scope, but they are hard to integrate and often need specialized skills to get working. On the other hand, tools like unstructured.io provide APIs for ingesting data. They are also single scope, but easy to integrate.
LLM orchestrators like LangChain and LlamaIndex have provide tools for doing lots of tasks. However, since their scope is very broad, it is very difficult to integrate them into an existing application due to differing APIs, compatibility issues, and maintenance complexities.
On the other hand, RAGaaS tools like Graphlit are an end-to-end solution. They are fully hosted, making it easy to integrate into your existing stack. RAGaaS tools offer a unified platform that simplifies the integration and management of all these components, making developing RAG applications more efficient and less stressful.
A Minimal RAGaaS Example
Let’s take a look at a simple Graphlit app, where we scrape a webpage, add it to a vector database and then use an LLM to ask a question related to it.

When you ingest a webpage using Graphlit’s ingest_uri method, Graphlit takes care of chunking the ingested data, indexing that into a vector database and finding relationships between other data in your database.

Graphlit will find relevant context from your indexed data for each query and add it to the prompt. Graphlit also manages conversations, so you don’t have to.
The model's response is what you would expect from a typical RAG application. Graphlit makes it easy to build A RAG application without integrating multiple tools and APIs. With RAGaaS, the challenges associated with building and maintaining a RAG system is abstracted away, allowing development teams to focus on their core application logic and business goals.