
Benchmarking ScaleDown’s Classification SLM for Model Routing
A task-specific small model outperforms GPT-5.4 Nano and Mini on intent classification, at 200x lower cost.

Model routing is becoming a standard pattern in production LLM systems. Instead of sending every query to a single frontier model, a router classifies the incoming request and directs it to the most appropriate model or pipeline. The routing decision might be based on task complexity, domain, required capabilities, or cost constraints.
The router sits upstream of everything else. It’s the highest-volume, most latency-sensitive component in the pipeline, and most teams are still using a frontier LLM for it, burning tokens on a classification task that doesn’t need generative capabilities at all.
We benchmarked ScaleDown’s classification SLM against OpenAI’s GPT-5.4 Nano and GPT-5.4 Mini on a model routing task to see how a purpose-built classifier compares to general-purpose LLMs.

The Benchmark
The task is multi-class intent classification: given an input query, classify it into the correct routing category. This mirrors the real-world pattern where an orchestration layer decides which downstream model, tool, or pipeline should handle a given request.
We evaluate on accuracy (percentage of queries correctly classified) and total cost for the benchmark run. Both matter for production use cases: a cheaper model that misroutes 20% of queries creates downstream costs far exceeding any token savings.
Results
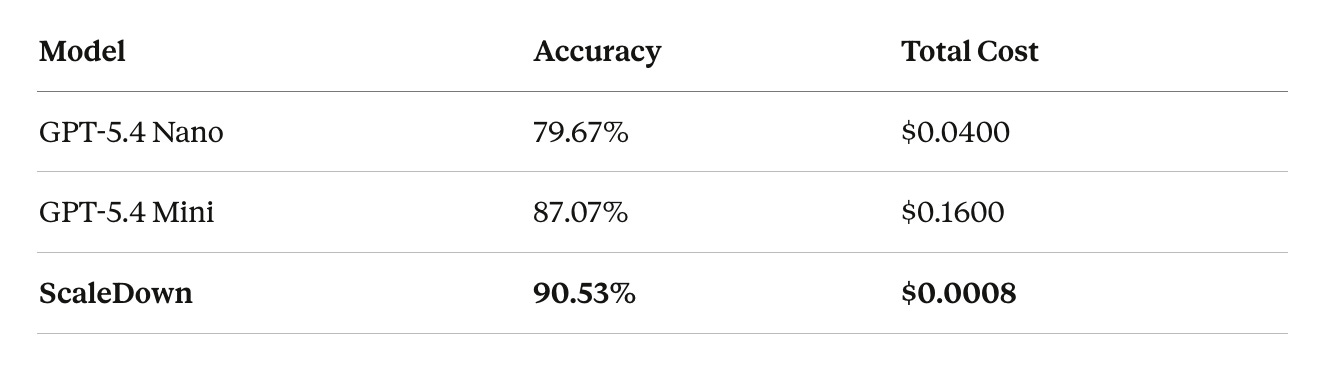
ScaleDown is the most accurate
At 90.53%, it outperforms both GPT-5.4 Mini (+3.46 points) and GPT-5.4 Nano (+10.86 points). This isn’t surprising if you’ve worked with task-specific models before: a small model trained specifically for classification on a well-defined taxonomy will typically beat a generalist model that has to infer the classification schema from a prompt.
The cost difference
ScaleDown’s total benchmark cost was $0.0008, roughly 50x cheaper than GPT-5.4 Nano and 200x cheaper than Mini. At production volumes, this difference compounds fast. A system processing 1M classification calls per day would spend roughly $1,000/day with Mini, $250/day with Nano, and $0.50/day with ScaleDown.
No accuracy-cost tradeoff
Typically, when you move from a larger model to a smaller one, you accept lower accuracy for lower cost. Here, the smallest and cheapest model is also the most accurate. This is the core argument for task-specific SLMs: when the task is well-defined and doesn’t require generation, a purpose-built classifier dominates on both axes.
Why LLMs Underperform on Classification
It’s worth understanding why GPT-5.4 Nano and Mini score lower on what seems like a straightforward task. There are a few factors at play.
First, LLMs solve classification indirectly. They generate a text response that happens to contain a class label. The model has to parse the prompt, understand the taxonomy, reason about the mapping, and produce the right token. A classifier scores each class directly and picks the highest one.
Second, LLMs are sensitive to prompt engineering. The classification accuracy of a frontier model depends heavily on how the taxonomy is described, how examples are formatted, and how the output format is specified. Small changes in the system prompt can swing accuracy by several points.
Third, generalist models over-interpret. When a user query contains domain-specific language, a frontier model’s broad knowledge can cause it to infer more nuance than the routing taxonomy requires. A query about “Roth conversions” might get classified into a tax optimization category when the routing schema just needs “retirement planning.”
Where This Matters
Model routing is the most obvious use case, but the same classification SLM applies anywhere you’re using an LLM for what is fundamentally a categorization task:
Intent classification in conversational AI. When a financial planning assistant needs to determine whether a user is asking about retirement, tax optimization, or insurance, that’s a routing decision, not a generation task. We covered this use case in depth in our previous post on intent classification for financial planners.
Content moderation and filtering. Classifying user inputs as safe/unsafe, on-topic/off-topic, or into content categories before they reach downstream processing.
Document triage. Routing incoming documents to the correct processing pipeline based on document type, urgency, or department.
In all of these, the classification call is high-volume, latency-sensitive, and doesn’t require text generation. Replacing the LLM with a task-specific classifier improves all three dimensions simultaneously: accuracy goes up, cost goes down, latency drops.
Key Takeaways
Classification is the wrong task for a generalist LLM. When the job is mapping inputs to a fixed rubric, a task-specific SLM is faster, cheaper, and more accurate.
The benchmark numbers tell a clear story: 90.53% accuracy at $0.0008, versus 87.07% at $0.16 for the next best option. That’s better accuracy at 0.5% of the cost. At scale, this is the difference between classification being a rounding error in your infrastructure budget and being a meaningful line item.
We offer 50M free tokens for every agent. Try the classification endpoint at scaledown.ai.