
Newsletter - Adaptable MLOps Architecture for Research Labs
The Tale of Adaptability in a World of Research with Changing Use Cases

Welcome to another edition of our exploration into the vast, intricate universe of Machine Learning Operations (MLOps) with a special focus on its application in research labs. Today, as you pause from your exciting computational pursuits, we invite you to explore the potential and versatility of our proposed MLOps architecture for research labs through three compelling case studies.

Picture the hustle and bustle of a dynamic research lab with numerous scholars delving into various aspects of a project. Imagine the daunting challenge of fine-tuning large language models in environments bereft of high-performance computing resources. Or consider the laborious task of an ML researcher, burdened with the frequent hyperparameter and data changes with no way to know how a model was trained.
Yes, these scenarios could be overwhelming, but here's where our proposed architecture comes to the rescue, blending collaboration tools, cloud computing platforms, and automation seamlessly. We'll guide you through how this robust infrastructure transforms daunting challenges into managed processes, thereby enhancing the efficiency and reproducibility of your research endeavours.
Adapting MLOps for Diverse Research Scenarios: Three Case Studies
In our initial blog, we unveiled our proposed MLOps architecture. Now, we demonstrate how it can be adapted to suit various use cases and constraints.

Architecture Implementation
To see what this might look like, you can check out our GitHub Repo. We use GitHub Actions to coordinate tasks. For instance, we have an action that uses Prefect to run your training tasks on your HPC. During the training process, training logs and model artefacts are saved in MLFlow. MLFlow is also used as a model registry from where it can be deployed to SageMaker. Finally, we propose using a plotly dash to show training results.
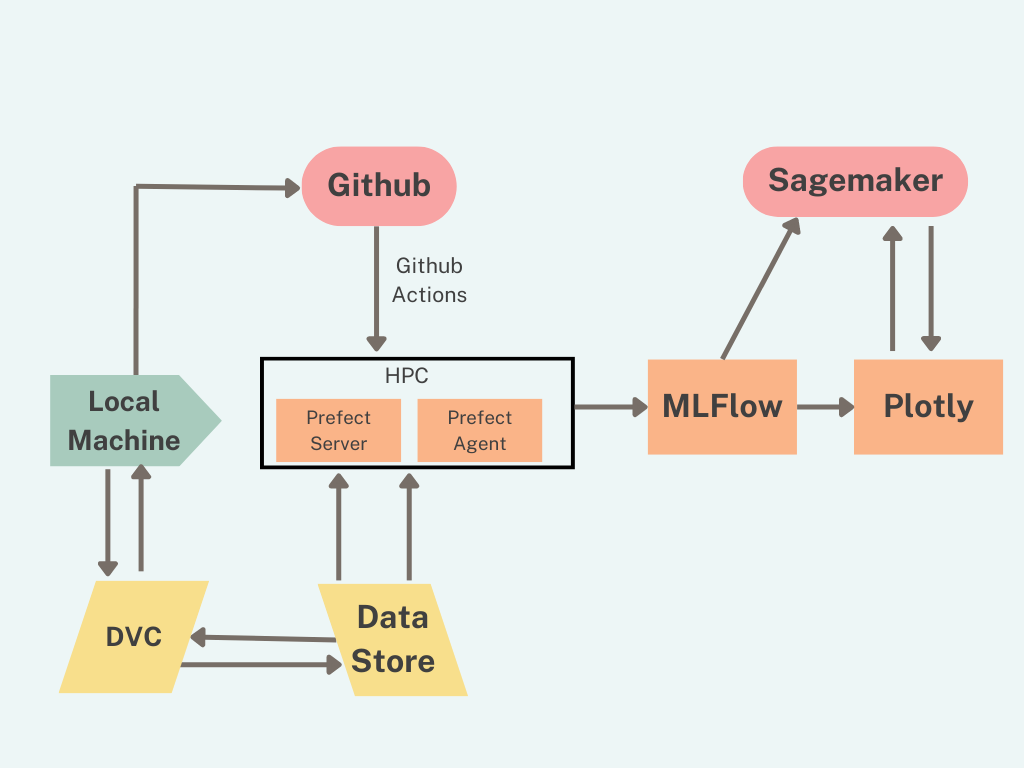
We think our proposed architecture can adapt to constraints different research labs will have. For instance, some labs may not have access to an HPC. Other labs may be limited to using only certain tools. To demonstrate this flexibility, below we discuss three scenarios.
Multiple Chefs, One Soup: The Chaos of Collaborative Research
Research labs often grapple with collaboration challenges due to multiple researchers working on various project aspects. With the adaptable MLOps architecture, GitHub serves as a cooperative platform, enhancing transparency in code development and fostering insightful discussions. With DVC and MLFlow, data and model versioning become seamless, allowing for efficient progress tracking. MLFlow also allows you to track the results of each model. If your lab is limited to one HPC, then Prefect serves as the orchestrator making sure that only one task is running at a time and that high-priority tasks can be bumped up the queue. A shared Plotly dashboard connected to MLFlow facilitates the visual representation of model performance, enabling informed collective decision-making.
GPU-Less Lab
With the rise of LLMs more and more researchers are working on training, fine-tuning and optimizing LLMs. The task of working with large language models can become challenging without high-performance computing resources. However, it is still possible to fine-tune or optimize them on a small-ish PC. If even that is not available to you, then you might have to use a cloud service. Here's where our flexible MLOps architecture shines by leveraging cloud computing platforms like AWS, Azure, or GCP. Researchers script the fine-tuning process, and Prefect handles the cloud execution. GitHub ensures the script's version control, while DVC and MLFlow maintain reproducibility through meticulous data and model versioning. Post-training, Plotly enables results visualization, and the final model can be deployed via a service like AWS SageMaker.
The Overburdened ML Researcher
Manual redeployment of models that require frequent updates can be tiresome. In such scenarios, our MLOps setup proves instrumental by using GitHub Actions for automation. Changes to the training script trigger a training job on an HPC or cloud platform. Post-training, MLFlow logs the model and its metadata. Successful training subsequently triggers another GitHub Action, automating the deployment to AWS SageMaker, Google AI Platform, or even a Raspberry Pi. Prefect keeps a vigilant eye on the health of the automated pipeline, alerting about task failures.
These case studies clearly show that our proposed MLOps architecture can adapt to various needs and constraints, thereby enhancing the efficiency and reproducibility of research.
MLOps and ML Pulse Check

Trusting the output from an LLM: The problem with LLM hallucinations is becoming more apparent as more and more people are deploying LLM products. There is also the problem of prompt injection attacks affecting the output from the LLM as well. A few weeks ago, independent security researcher Simon Wilson suggested using a dual LLM architecture to solve this issue. However, this solution is not without issues, the biggest one being the cost of running a second LLM.
Recently, Vincent suggested a new solution that I really like. he suggested using a custom domain-specific model to verify the output of an LLM. If the outputs are similar, then we don’t need to worry. However, if the outputs are significantly different, then we can review those outputs and use them for retraining.

Watermarking LLM Outputs: Google recently emphasized the significance of being able to distinguish generated text and images at its latest I/O event, stressing the need to curb misinformation. Presently, it is quite a challenge to determine whether a piece of text has been generated by an LLM. A proposed solution, as detailed in a new paper, introduces the concept of embedding a 'watermark' within the LLM's outputs, serving as a definitive marker for generated text. This watermarking technique does not compromise the quality of the output and requires a secret key to detect whether the text was generated. However, there may be potential limitations; for instance, the watermarking could potentially be bypassed if an unwatermarked LLM rewrites the original content. Despite this, the prospect of watermarking holds exciting possibilities. For example, we could develop tools similar to a Chrome extension we built before that, rather than generating LLM text, could identify and block content produced by an LLM - essentially functioning as an AdBlock, but for generated content.
The effectiveness of generated text for training models: A recent research paper by scholars from multiple universities has demonstrated a somewhat intuitive but previously unquantified concept about the training of models using data generated by another model. The study reveals that such a practice will inevitably lead to a decline in the model's performance over time. Essentially, suppose a model is persistently trained only on data with a specific distribution derived from a different model. In that case, it will gradually conform to this new distribution and "forget" the original one. Worryingly, the biases inherent in the generative model will become amplified in the model undergoing training. This issue is poised to become an increasing challenge as a greater proportion of content on the internet will be generated by LLMs, which will subsequently be used to train the next generation of LLMs.
