
Generative AI 101 for Language Models: LLMs Made Easy & Exciting!
Discovering how GPT Models Think and How They Work

Hello there!
Ever wondered how ChatGPT manages to produce human-like text? Have you found yourself in a conversation about ChatGPT and couldn't quite grasp what it was all about? Or perhaps your workplace or research lab is considering the use of GPT APIs, and you're unsure where to start?
Maybe you've read our previous newsletters and found them a bit too complex. If any of this resonates with you, we've got some great news!
We have heard your requests and understand the challenges beginners face in this dynamic field of Generative AI and Language Models. We're thrilled to announce two fresh blogs that serve as an easy-to-understand guide to Large Language Models (LLMs) and their fine-tuning!
Blog 1: Generative AI 101 - Demystifying Large Language Models
In this beginner-friendly blog, we demystify the enigma behind Large Language Models like ChatGPT. We start with the basics, explain what LLMs are, how they work, and gradually unravel their myriad applications. This blog is your perfect stepping stone into the world of Generative AI and LLMs.
Link: Generative AI 101 - LLMs Unveiled
Blog 2: Learning the Art of Fine-tuning Large Language Models
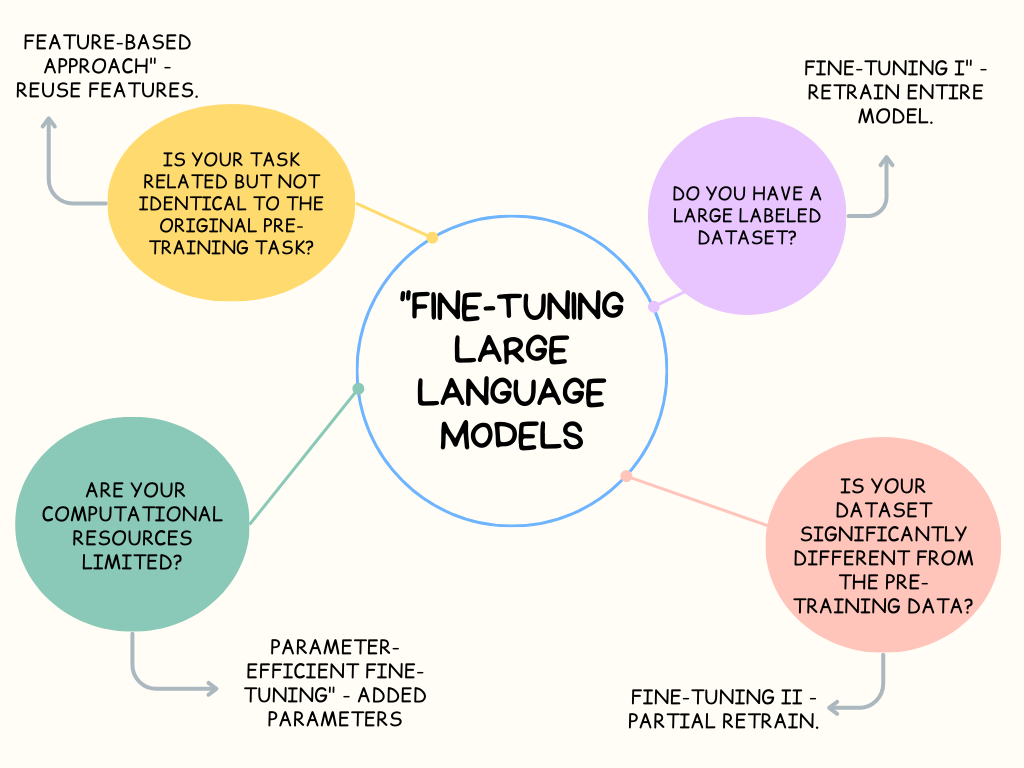
Our second blog addresses the pivotal process of fine-tuning these powerful models. We've stripped down the complexity and explained the concept in a relatable way. This guide uncovers why and how fine-tuning is performed, explores different methodologies, and highlights the emerging concept of 'parameter-efficient fine-tuning.
Intro to LLM Series with Women Who Code
These two blogs are an essential part of our ongoing initiative to bring the fascinating world of Generative AI and LLMs to everyone, irrespective of their technical background.
Also, we are excited to announce that we have partnered with Women Who Code (WWCode) for a special series on AI. If you're keen to delve deeper and engage in insightful discussions, please join us in the WWCode sessions. You can also catch us live or watch recorded sessions on our YouTube channel.
MLOps and ML Pulse Check

Distilling Guardrail Models: LLM hallucinations, prompt attacks and unrelated answers are becoming bigger issues now that more and more companies are deploying LLM applications. This has prompted the release of tools like Evals and Guardrails. Another pattern that is emerging to solve these issues is to use a second LLM model to check the generated output for incorrect or harmful responses. In a new paper by researchers from Curai, a smaller distilled model finetuned on LLM output data is used as a guardrail model. They use the outputs from GPT-4 to distill into a GPT-3 model. The resulting GPT-3 guardrail model is faster, cheaper and better than the original GPT-4 model!
The role of ML Engineers when using LLM APIs: In this talk, Richard Socher, the founder of You.com, talks about the need for ML Engineers in this era where LLM APIs are easier to build and deploy than custom models while still maintaining reasonable performance. In our previous article, we talked about how the skyrocketing price of API calls will eventually force companies to build custom models.